
데이터 기반 VOC 분석 및 자동화 대시보드 구축: 비용 절감과 효율성 극대화
“사내 구성원 분들이 젠데스크 고객 문의 내역 팔로업에 어려움을 겪고 있다는 사실을 공유 받아, 이를 해결하기 위해 Redash VOC 대시보드를 구축했습니다. 젠데스크 데이터를 자동으로 수집하고 전처리한 후, OpenAI API를 활용해 고객 문의 내역을 주제별로 분류하고 요약했습니다. 추가적으로, 매주 월요일마다 가장 많이 증가한 문의 주제를 슬랙으로 알림을 보내어, 고객 이슈를 효율적으로 식별하고 대응할 수 있도록 기여했습니다. 결과적으로 매월 약 $275 기회 비용을 제거할 수 있었으며, 사내 구성원 분들의 VOC 팔로업 시간을 감소시키는 성과를 얻었습니다.”
| Performance Summary |
|---|
- 기회 비용 절감: $300/월 → $25/월 (92% ↓) |
목차
- STAR Summary
- Situation
- Tasks
- Actions
- Results
1. STAR Summary
Situation
- 사내 구성원 분들이 젠데스크 고객 문의 내역을 효율적으로 추적하고 팔로업하는 데 어려움을 겪고 있었습니다. 모든 내역을 읽는 것은 지나치게 많은 시간과 노력을 요구했으며, 외부 VOC 분석 서비스를 도입하기에는 비용의 부담이 있었습니다.
Tasks
- 고객 문의 내역의 주제를 분류하고 요약하여, Redash VOC 대시보드를 만들기로 결정했습니다.
- 가장 긴급한 고객 문의 주제를 알려주는 슬랙 알림 봇을 구축하기로 결정했습니다.
Actions
-
데이터 파이프라인
1.1. 데이터 수집 및 전처리
(Zendesk Tickets → Google Sheets → BigQuery)1.2. 주제 분류
(OpenAI API)1.3. 요약하기
(OpenAI API) -
대시보드와 알림 봇
2.1. 대시보드 만들기
(BigQuery → Redash)2.2. 알림 봇 구축하기
(BigQuery → Slack API)
Results
- 비용 절약
- 월 $300 비용의 외부 서비스를 도입하지 않고도, 내부 개발을 통해 월 $25 비용 만으로 문제를 해소했습니다.
- 시간 절감
- 사내 구성원 분들의 VOC 팔로업, 이슈 식별과 대응 속도를 향상시켰습니다.
2. Situation
사내 구성원 분들이 젠데스크 고객 문의 내역을 효율적으로 추적하고 팔로업하는 데 어려움을 겪고 있었습니다. 모든 내역을 읽는 것은 지나치게 많은 시간과 노력을 요구했으며, 외부 VOC 분석 서비스를 도입하기에는 비용의 부담이 있었습니다.
구체적인 상황
- 매주 수십-수백개의 고객 문의 내역을 일일이 팔로업하는 과정에서 너무 많은 시간이 소모되고 있었습니다.
- 정확히 어떤 항목이 CX에 악영향을 끼치고 있는지 흐름을 파악하기 어려웠습니다.
사내 구성원 분들의 말말말
- 임원 1: “주기적으로 문의 내역을 읽으며 고객의 감을 잡아가고 있는데, 양이 너무 많아 시간 소모가 커요.”
- 임원 2: “VOC 분석을 위한 외부 서비스를 도입하고 싶지만 가격이 너무 비싸서 고민하고 있어요.”
- CX 담당자: “CX 및 VOC 현황을 좀 더 많은 동료들에게 공유하고, 이슈 대응 속도를 개선하고 싶어요.”
3. Tasks
- 고객 문의 내역의 주제를 분류하고 요약하여, Redash VOC 대시보드를 만들기로 결정했습니다.
- 가장 긴급한 고객 문의 주제를 알려주는 슬랙 알림 봇을 구축하기로 결정했습니다.

4. Actions
데이터 파이프라인
1.1. 데이터 수집 및 전처리
(Zendesk Tickets → Google Sheets → BigQuery)1.2. 주제 분류
(OpenAI API)1.3. 요약하기
(OpenAI API)대시보드와 알림 봇
2.1. 대시보드 만들기
(BigQuery → Redash)2.2. 알림 봇 구축하기
(BigQuery → Slack API)
1. 데이터 파이프라인
1.1. 데이터 수집 및 전처리 (Zendesk Tickets → Google Sheets → BigQuery)

1) 먼저 Google Workspace Marketplace에서 제공하는 Zendesk Connector를 통해 답변이 완료된 젠데스크 티켓 데이터를 사내 비공개 구글 시트에 자동으로 저장될 수 있도록 설정했습니다.

2) Python에서 구글 시트 데이터를 로드했습니다.
코드 확인하기
# 구글 시트 Raw Data 불러오기 (to `df`)
gc = gspread.service_account(google_sheets_credentials_fpath)
spreadsheet = gc.open_by_url(google_sheets_url)
sheet = spreadsheet.worksheet(google_sheets_worksheet_name)
sheet_data = sheet.get_all_records()
df = pd.DataFrame(sheet_data)
3) 그런 후, 데이터 전처리를 진행했습니다.
필요한 칼럼만 필터링
# 칼럼 이름 재정의하기
df = df.rename(
columns={
'created_at': 'created_datetime',
'raw_subject': 'subject',
'tags.0': 'zendesk_topic',
'updated_at': 'updated_datetime'
}
)
# 필요한 칼럼만 뽑아내기
df = df[[
'id',
'created_datetime',
'zendesk_topic',
'subject',
'description'
]]
시간대 변경 (UTC → KST)
# 기존 타임스탬프: UTC to KST 변환해주기
kst = pytz.timezone('Asia/Seoul')
df['created_datetime'] = pd.to_datetime(df['created_datetime'], utc=True).dt.tz_convert(kst).dt.tz_localize(None)
df = df.astype('str') # BigQuery에 Load할 때, 기본적으로 모두 String 타입이 되어야 하므로, 어쩔 수 없이 모두 String으로 Casting한다.
신규 항목들만 필터링
# 이미 타겟 테이블에 존재하는 행을 제거해주기 (중복 방지)
query = f'SELECT DISTINCT id FROM `{bigquery_tickets_table_id}`'
try:
existing_ids = client.query(query).to_dataframe()
existing_ids = set(existing_ids['id'])
df = df[
~ df['id'].isin(existing_ids)
].reset_index(drop=True)
except:
df = df
4) 마지막으로 BigQuery 테이블에 적재했습니다.
코드 확인하기
# 빅쿼리 테이블에 적재하기
table = client.get_table(bigquery_tickets_table_id)
client.load_table_from_dataframe(df, table)
1.2. 주제 분류 (OpenAI API)

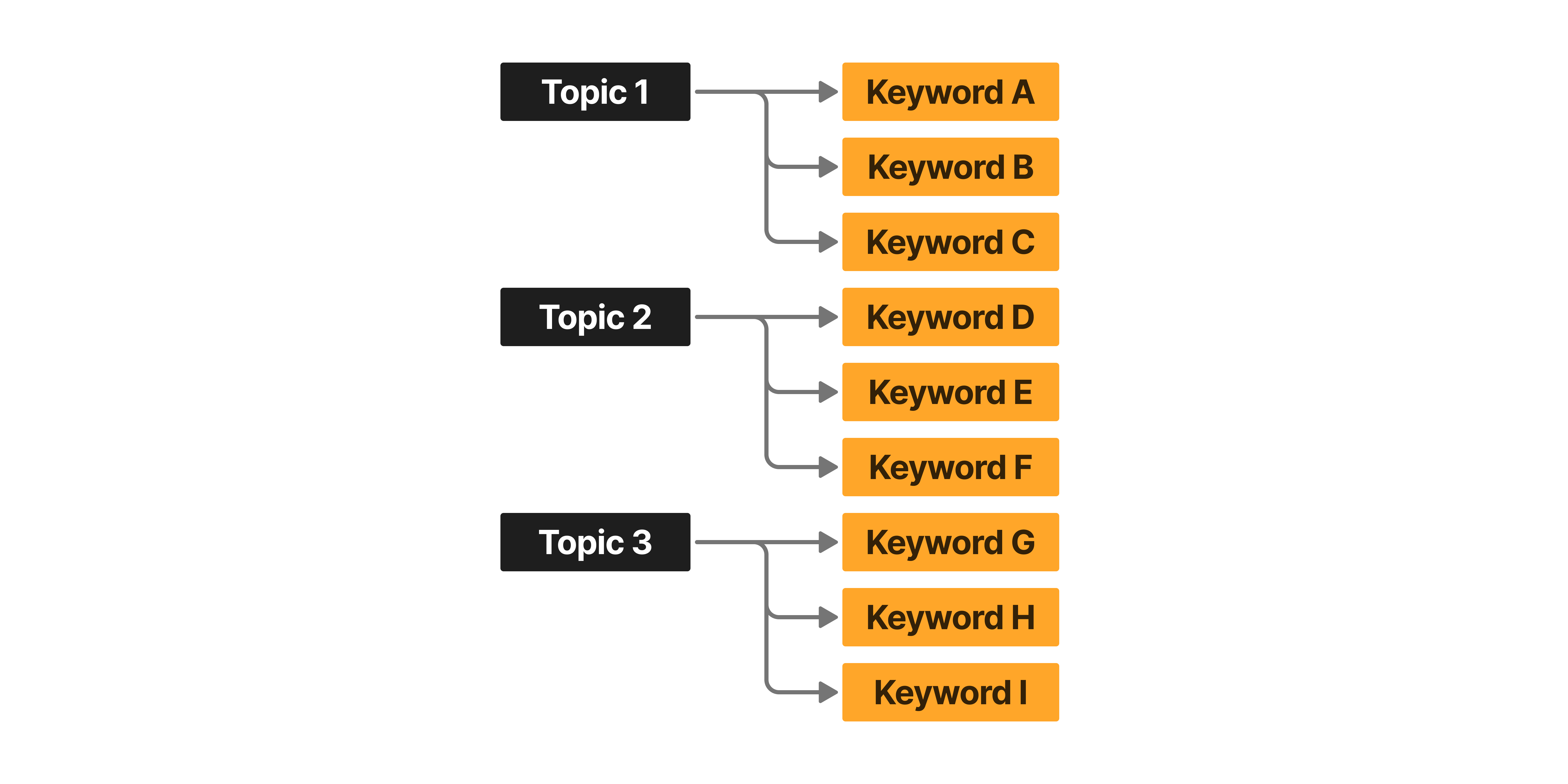
1) 분류할 주제 목록을 사전에 정의하기 위해, CX 담당자 및 UX/UI 디자이너 분과 함께 논의 후 분류 체계를 세웠습니다.
- Topic: 넓은 범주의 주제
- Keyword: 구체적인 세부 주제
2) Python에서 BigQuery 테이블의 데이터를 로드했습니다.
코드 확인하기
# BigQuery `tickets` 테이블 불러오기 (to `df`)
query = f'SELECT * FROM {bigquery_tickets_table_id}'
df = bigquery_client.query(query).to_dataframe()
3) 그 중, 신규 항목들만 필터링했습니다.
코드 확인하기
# 이미 타겟 테이블에 존재하는 행을 제거해주기 (중복 제거)
query = f'SELECT DISTINCT id FROM `{bigquery_tickets_topics_table_id}`'
try:
existing_ids = bigquery_client.query(query).to_dataframe()
existing_ids = set(existing_ids['id'])
df = df[
~ df['id'].isin(existing_ids)
].reset_index(drop=True)
except:
df = df
4) OpenAI에 요청할 프롬프트를 작성했습니다.
System Prompt
당신의 작업은 고객 문의 내역에서 하나의 핵심 키워드를 분류하는 것입니다.
오로지 주어진 토픽 목록에서만 선택하여 응답해야 합니다.
아래는 당신이 선택할 수 있는 토픽 목록입니다:
{키워드 리스트}
다른 토픽을 생성하거나 선택하지 마세요.
User Prompt
아래는 고객 문의 내역입니다.
이 텍스트에서 하나의 핵심 토픽을 추출하세요.
고객 문의 내역:
{실제 텍스트}
추출 형식: 토픽
제한 사항:
1. 오로지 토픽으로만 응답하세요.
2. 주어진 토픽 목록에서만 선택하세요. 다른 토픽을 생성하거나 선택하지 마세요.
3. 반드시 아래 목록에서 하나를 선택하세요:
{키워드 리스트}
추출 결과:
5) 각 티켓을 순회하며 OpenAI 주제 분류 작업을 진행했습니다.
코드 확인하기
# OpenAI에 요청할 시스템 프롬프트 정의하기
prompt_system = f'''
당신의 작업은 고객 문의 내역에서 하나의 핵심 키워드를 분류하는 것입니다.
오로지 주어진 토픽 목록에서만 선택하여 응답해야 합니다.
아래는 당신이 선택할 수 있는 토픽 목록입니다:
{', '.join(topics2_list)}
다른 토픽을 생성하거나 선택하지 마세요.
'''
# 각 행을 돌아가면서 OpenAI API Request 시작하기
topic2_results_list = []
for i in range(len(df)):
# 주제 + 본문
text = df.loc[i, 'subject'] + ' ' + df.loc[i, 'description']
text = text[:2000] # 2,000개 길이로 제한 (비용 절약)
# 개별적으로 요청할 프롬프트 정의
prompt_individual = f'''
아래는 고객 문의 내역입니다.
이 텍스트에서 하나의 핵심 토픽을 추출하세요.
고객 문의 내역:
{text}
추출 형식: 토픽
제한 사항:
1. 오로지 토픽으로만 응답하세요.
2. 주어진 토픽 목록에서만 선택하세요. 다른 토픽을 생성하거나 선택하지 마세요.
3. 반드시 아래 목록에서 하나를 선택하세요:
{', '.join(topics2_list)}
추출 결과:
'''
# API Request 시작
result = openai_client.chat.completions.create(
model = 'gpt-4',
max_tokens = 500,
n = 1,
temperature = 0,
stop = None,
messages = [
{"role": "system", "content": prompt_system},
{"role": "user", "content": prompt_individual}
]
)
# 토픽 결과를 Empty Lists에 기록하기
topic2_result = result.choices[0].message.content.replace('\'', '').replace('\"', '').replace('[', '').replace(']', '').strip()
topic2_results_list.append(topic2_result)
# 토픽 2 결과를 통해 토픽 1 결과도 기록하기
topic1_results_list = []
for topic2 in topic2_results_list:
for i in range(len(topics_list)):
if topics_list[i][1] == topic2:
topic1_results_list.append(topics_list[i][0])
break
if i == len(topics_list) - 1:
topic1_results_list.append('Others')
# df에 토픽 1, 토픽 2 칼럼을 추가하고, 필요한 칼럼만 뽑아내기
df['openai_topic_1'] = topic1_results_list
df['openai_topic_2'] = topic2_results_list
df = df[[
'id',
'created_datetime',
'openai_topic_1',
'openai_topic_2'
]]
6) 마지막으로, 주제 분류 결과를 BigQuery 테이블에 적재했습니다.
코드 확인하기
# 빅쿼리 테이블에 적재하기
table = bigquery_client.get_table(bigquery_tickets_topics_table_id)
bigquery_client.load_table_from_dataframe(df, table)
1.3. 요약하기 (OpenAI API)

1) Python에서 BigQuery 테이블의 데이터를 로드했습니다.
코드 확인하기
# BigQuery `tickets` 테이블 불러오기 (to `df`)
query = f'SELECT * FROM {bigquery_tickets_table_id}'
df = bigquery_client.query(query).to_dataframe()
2) 그 중, 신규 항목들만 필터링했습니다.
코드 확인하기
# 이미 타겟 테이블에 존재하는 행을 제거해주기 (중복 제거)
query = f'SELECT DISTINCT id FROM `{bigquery_tickets_summary_table_id}`'
try:
existing_ids = bigquery_client.query(query).to_dataframe()
existing_ids = set(existing_ids['id'])
df = df[
~ df['id'].isin(existing_ids)
].reset_index(drop=True)
except:
df = df
3) OpenAI에 요청할 프롬프트를 작성했습니다.
System Prompt
당신의 작업은 고객 문의 내역을 한국어 한 문장으로 요약하는 것입니다.
블록체인 하드웨어 및 앱 지갑 서비스 기업의 고객임을 기억하세요.
요약은 반드시 한국어 한 문장으로 제공되어야 하며, 민감한 개인정보나 링크는 반드시 제거되어야 합니다.
User Prompt
아래는 고객 문의 내역입니다.
이 텍스트를 한국어 하나의 문장으로 요약하세요.
고객 문의 내역:
{실제 텍스트}
추출 형식: 한국어 한 문장
제한 사항:
1. 블록체인 하드웨어 및 앱 지갑 서비스 기업의 고객임을 기억하세요.
2. 반드시 한국어로 요약하세요. (단, 번역이 불가능한 고유 단어는 영어 가능)
3. 오로지 한 문장으로만 응답하세요.
4. 민감한 개인정보는 반드시 제거하세요.
추출 결과:
4) 각 티켓을 순회하며 OpenAI 요약 작업을 진행했습니다.
코드 확인하기
# OpenAI에 요청할 시스템 프롬프트 정의하기
prompt_system = '''
당신의 작업은 고객 문의 내역을 한국어 한 문장으로 요약하는 것입니다.
블록체인 하드웨어 및 앱 지갑 서비스 기업의 고객임을 기억하세요.
요약은 반드시 한국어 한 문장으로 제공되어야 하며, 민감한 개인정보나 링크는 반드시 제거되어야 합니다.
'''
# 각 행을 돌아가면서 OpenAI API Request 시작하기
summaries_list = []
for i in range(len(df)):
# 주제 + 본문
text = df.loc[i, 'subject'] + ' ' + df.loc[i, 'description']
text = text[:2000] # 2,000개 길이로 제한 (비용 절약)
# 개별적으로 요청할 프롬프트 정의
prompt_individual = f'''
아래는 고객 문의 내역입니다.
이 텍스트를 한국어 하나의 문장으로 요약하세요.
고객 문의 내역:
{text}
추출 형식: 한국어 한 문장
제한 사항:
1. 블록체인 하드웨어 및 앱 지갑 서비스 기업의 고객임을 기억하세요.
2. 반드시 한국어로 요약하세요. (단, 번역이 불가능한 고유 단어는 영어 가능)
3. 오로지 한 문장으로만 응답하세요.
4. 민감한 개인정보는 반드시 제거하세요. (예: 인적사항, 지갑주소, 연락처, 비밀번호, 개인키, 니모닉, 이메일 주소, IP 주소, URL, 소셜 미디어 계정 등)
추출 결과:
'''
# API Request 시작
result = openai_client.chat.completions.create(
model = 'gpt-4',
max_tokens = 200,
n = 1,
temperature = 0,
stop = None,
messages = [
{"role": "system", "content": prompt_system},
{"role": "user", "content": prompt_individual}
]
)
# 토픽 결과를 Empty Lists에 기록하기
summary_result = result.choices[0].message.content.replace('\'', '').replace('\"', '').replace('[', '').replace(']', '').strip()
summaries_list.append(summary_result)
# df에 요약 칼럼을 추가하고, 필요한 칼럼만 뽑아내기
df['openai_summary'] = summaries_list
df = df[[
'id',
'created_datetime',
'openai_summary'
]]
5) 마지막으로, 요약 결과를 BigQuery 테이블에 적재했습니다.
코드 확인하기
# 빅쿼리 테이블에 적재하기
table = bigquery_client.get_table(bigquery_tickets_summary_table_id)
bigquery_client.load_table_from_dataframe(df, table)
2. 대시보드와 알림 봇
2.1. 대시보드 만들기 (BigQuery → Redash)
1) 다음 내용을 지닌 Redash 대시보드를 생성했습니다.
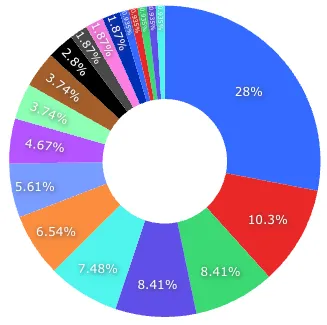
Topic별 비율
Topic별 트렌드

Keyword별 트렌드
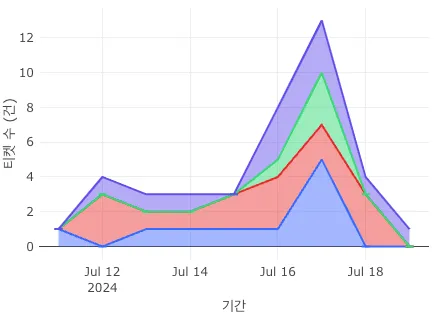
Keyword별 문의 요약
전체 데이터

2.2. 알림 봇 구축하기 (BigQuery → Slack API)
1) 우선, BigQuery 쿼리문을 작성했습니다.
전주에 고객 문의 수가 가장 많이 증가한 세부 주제(Keyword)를 추출 (전전주 대비)
WITH
CTE_1w_ago_raw AS (
SELECT
openai_topic_2,
COUNT(DISTINCT id) AS tickets_cnt
FROM
`bigquery_tickets_topics_table_id`
WHERE
DATE_TRUNC(DATE_ADD(CURRENT_DATE(), INTERVAL -1 WEEK), WEEK) <= DATE(created_datetime)
AND DATE(created_datetime) < DATE_TRUNC(CURRENT_DATE(), WEEK)
AND openai_topic_1 != 'Others'
GROUP BY
1
),
CTE_2w_ago_raw AS (
SELECT
openai_topic_2,
COUNT(DISTINCT id) AS tickets_cnt
FROM
`bigquery_tickets_topics_table_id`
WHERE
DATE_TRUNC(DATE_ADD(CURRENT_DATE(), INTERVAL -2 WEEK), WEEK) <= DATE(created_datetime)
AND DATE(created_datetime) < DATE_TRUNC(DATE_ADD(CURRENT_DATE(), INTERVAL -1 WEEK), WEEK)
AND openai_topic_1 != 'Others'
GROUP BY
1
),
CTE_diff AS (
SELECT
COALESCE(MAIN.openai_topic_2, COMP.openai_topic_2) AS openai_topic_2,
MAIN.tickets_cnt AS tickets_cnt_1w_ago,
COALESCE(COMP.tickets_cnt, 0) AS tickets_cnt_2w_ago,
COALESCE(MAIN.tickets_cnt - COMP.tickets_cnt, 0) AS tickets_cnt_diff
FROM
CTE_1w_ago_raw MAIN
LEFT JOIN
CTE_2w_ago_raw COMP
ON MAIN.openai_topic_2 = COMP.openai_topic_2
)
SELECT
openai_topic_2,
tickets_cnt_1w_ago,
tickets_cnt_2w_ago,
tickets_cnt_diff
FROM
CTE_diff
WHERE
tickets_cnt_diff = (SELECT MAX(tickets_cnt_diff) FROM CTE_diff)
AND tickets_cnt_diff > 0
ORDER BY
1
2) 슬랙 메시지 객체를 작성했습니다.
코드 확인하기
df = bigquery_client.query(query).to_dataframe()
# Slack 메시지 제목 만들기
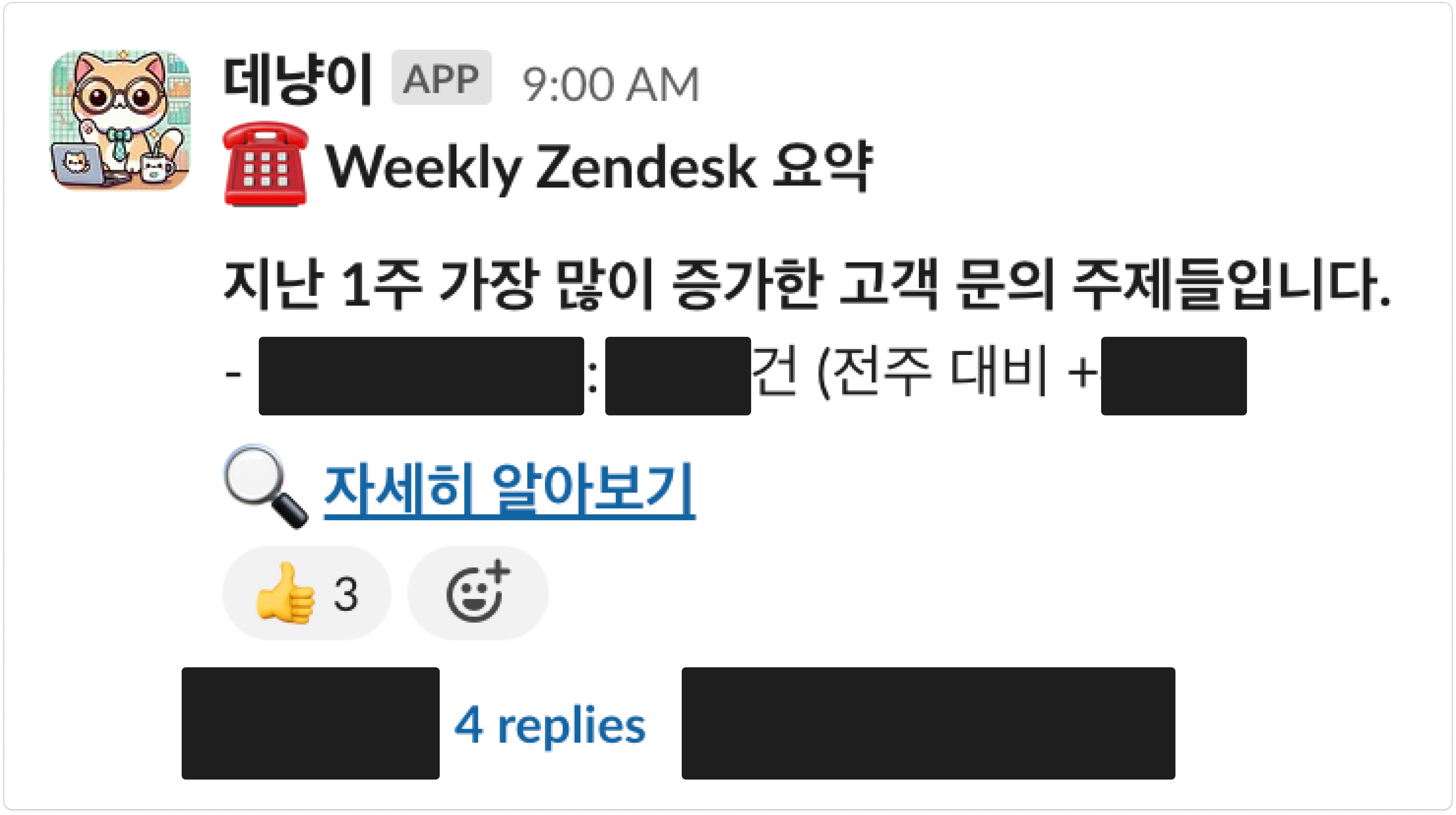
message = f':phone: *Weekly Zendesk 요약* \n\n'
message += f'*지난 1주 가장 많이 증가한 고객 문의 주제들입니다.* \n'
# 만약 데이터가 존재하는 경우
if len(df) > 0:
topics = df['openai_topic_2'].tolist()
tickets_cnt_1w_agos = df['tickets_cnt_1w_ago'].tolist()
tickets_cnt_diffs = df['tickets_cnt_diff'].tolist()
# Slack 메시지 만들기
for i, topic in enumerate(topics):
message += f'- *{topic}*: 총 {tickets_cnt_1w_agos[i]}건 (전주 대비 +{tickets_cnt_diffs[i]}) \n'
# 만약 데이터가 존재하지 않는 경우
else:
message += f'- *증가한 주제가 하나도 없어요.*:smile: \n\n'
3) 매주 월요일 9:00 AM KST에 다음과 같은 슬랙 알림이 발송되었습니다.
5. Results
- 비용 절약
- 월 $300 비용의 외부 서비스를 도입하지 않고도, 내부 개발을 통해 월 $25 비용 만으로 문제를 해소했습니다.
- 시간 절감
- 사내 구성원 분들의 VOC 팔로업, 이슈 식별과 대응 속도를 향상시켰습니다.
1. 비용 절약
결론) 내부 개발을 통해 매월 약 $275 기회 비용을 제거할 수 있었습니다.
| 외부 VOC 분석 서비스 | 내부 개발 | |
| 월간 비용 | $300 |
$25 |
1) 외부 VOC 서비스
- 도입을 고려 중이었던 syncly의 경우, 최소 월 $299의 비용이 요구되었습니다.

2) 내부 개발
- 그러나 직접 내부 개발은 다음과 같은 비용이 요구되었습니다.
| 리소스 | 월간 비용 |
| 1. OpenAI API | $25 |
| 2. BigQuery 스토리지 | 거의 없음 |
| 3. BigQuery 쿼리 사용 | 미미함 |
| 4. VM Instance 운영 | 기존 인스턴스를 사용하므로 한계비용 적음 |
| TOTAL | $25 + e |
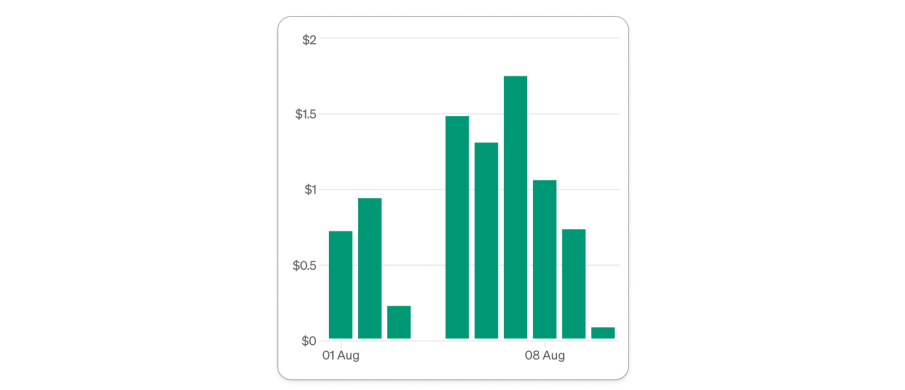
일별 OpenAI API 비용
2. 시간 절감
1) Redash VOC 대시보드 (주제 분류)
- 사내 구성원 분들의 VOC 이슈 식별 편의성을 향상시켰습니다.
2) Redash VOC 대시보드 (요약)
- 사내 구성원 분들의 VOC 팔로업 속도를 향상시키고 VOC에 대한 접근성을 개선했습니다.
3) 슬랙 알림 봇
- 매주 문의 수가 가장 많이 늘어난 주제를 사내 구성원 분들에게 공유함으로써, 이슈 식별과 대응 속도를 향상시키고 동일한 맥락을 공유하는 데 기여했습니다.
Published by Joshua Kim
