
데이터 분석가의 SQL 최적화 일기: Static vs. Rolling Stickiness
대고객 서빙을 위해 엄청나게 큰 사이즈의 소스 테이블로부터 최적화된 데이터 마트 설계 고민을 많이 하고 있는 만큼, Stickiness 지표 사례를 중심으로 SQL 성능에 대한 이야기를 들려드리겠습니다.
CONTENTS
- 들어가는 글
- Rolling MAU vs. 30일 이동평균선
- Static MAU
- Stickiness 지표
- Rolling Stickiness
- Static Stickiness
- Data Mart를 통해 Rolling MAU 도입하기
- 결론: Query Cost vs Data Freshness
DISCLAIMER
본 자료는 작성자 본인의 견해일 뿐이며, 실제 데이터베이스의 환경에 따라 적합하지 않을 수 있습니다. 이미지 출처를 제외한 모든 쿼리문과 내용은 본인의 경험에 의해 작성되었습니다. 작성된 쿼리문은 샘플로 작성한 것이며, 본인의 과거 및 현재 재직 회사의 업무 현황과 무관합니다.
1. 들어가는 글

안녕하세요. 저는 위 아이 처럼 데이터 분석가로 근무하고 있는 Joshua라고 합니다.
저는 일반적인 B2C 기업에서 데이터 분석가로 근무하며, GA4, Amplitude, BigQuery, Redash 등을 활용하여 A/B 테스트, 지표 모니터링 등을 수행하며 회사의 등대 역할을 하며 지냈습니다. 다른 분들과 비슷한 역할을 수행했던 것이죠.
또한 GA4, Amplitude 등과 같은 B2B 데이터 분석 플랫폼 서비스를 만드는 경험도 살짝 했는데요. 그러다보니 저의 R&R은 서비스 자체의 데이터 분석 업무 외에도, 고객들에게 데이터를 서빙하기 위한 데이터 마트 설계와 최적화 업무에 집중되기도 했습니다. 제 타이틀을 멋있게 가공하면 최근에 떠오르는 포지션인 Analytics Engineer, 반쪽 짜리 데이터 엔지니어, 아니면 대충 쿼리 머신 혹은 분지니어(?)인 것 같기도 합니다. 😅
아무튼 대고객 서빙을 위해 엄청나게 큰 사이즈의 소스 테이블로부터 최적화된 데이터 마트 설계 고민을 많이 하고 있는 만큼, Stickiness 지표 사례를 중심으로 SQL 성능에 대한 이야기를 들려드리겠습니다.
(SQL 전문가 분들이 많이 계시는 만큼, 제 글을 비판적으로 고찰해주시면 감사하겠습니다! 😄)
2. Rolling MAU vs. 30일 이동평균선
Rolling MAU란 마치 30일 이동평균선 인디케이터 등과 유사하게, 각 시점마다 최근 30일 동안의 MAU를 측정하는 지표입니다. 아래 GA4의 리포트는 WAU와 MAU를 모두 Rolling 방식으로 집계하고 있는 대표적인 사례라고 할 수 있을 것 같아서 가져와봤어요!
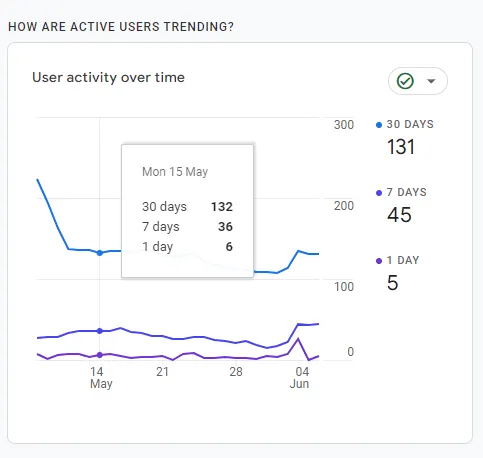
하지만, 30일 이동평균선 인디케이터와 Rolling MAU의 연산 방식에는 중대한 차이점이 있습니다.
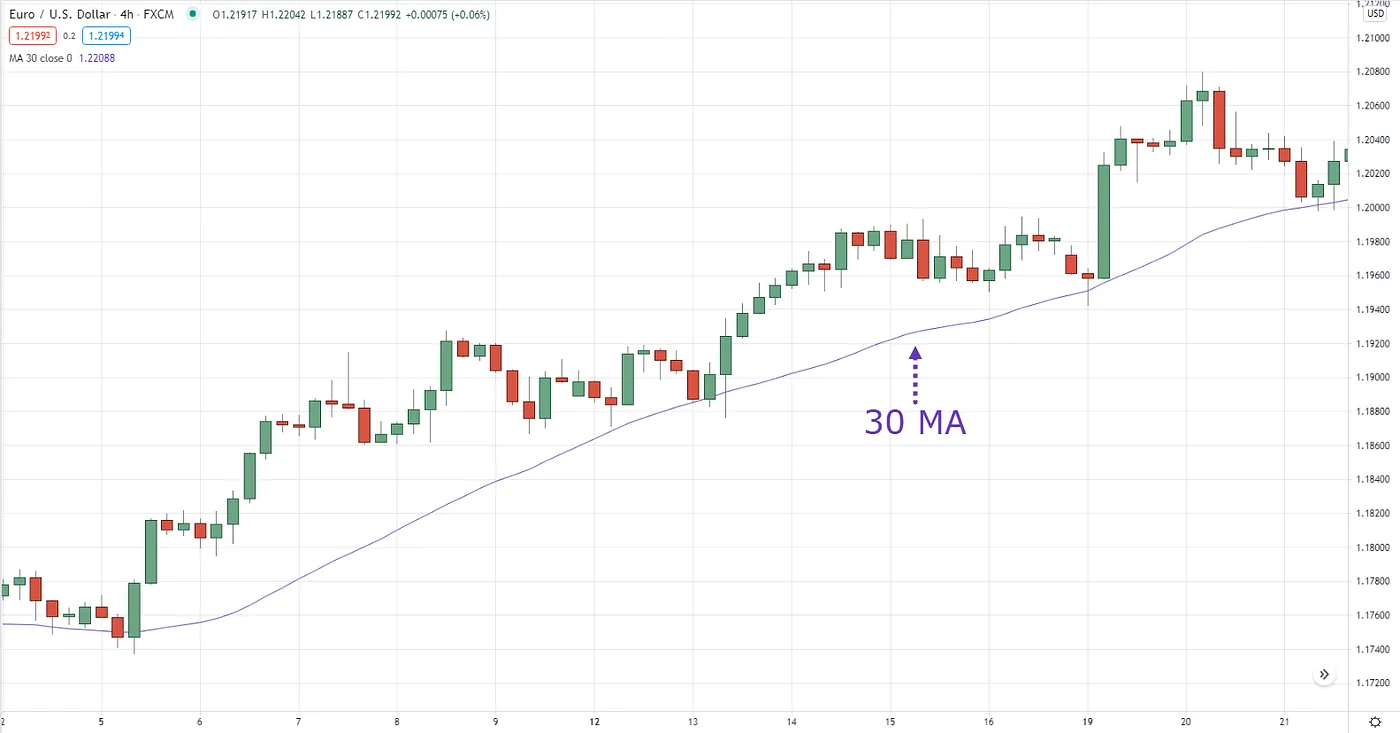
먼저 30일 이동평균선을 SQL스럽게 작성해본다면, 단순히 AVG Window Functions를 통해 즉각적으로 연산할 수 있습니다. Window Functions는 이미 출력된 price 칼럼 자체를 통해 연산하므로, daily_prices 테이블을 중복으로 불러오지 않아 연산량이 기하급수적으로 증가하지 않습니다.
WITH
CTE_ma_30d AS (
SELECT
date,
price,
AVG(price) OVER (
ORDER BY date
ROWS BETWEEN 29 PRECEDING AND CURRENT ROW
) AS ma_30d
FROM
daily_prices
ORDER BY
1
)
SELECT
*
FROM
CTE_ma_30d
;
반면, Rolling MAU의 연산 방식은 중대한 문제점이 있습니다. 즉, Window Functions를 통해 연산하는 것이 어렵다는 점입니다. 아래 쿼리문을 살펴보면, SELECT Statement 내 서브쿼리를 통해 Outer Table의 각 date마다 일일이 Inner Table의 가변적인 기간마다 모든 user_id 고유값 개수를 COUNT하게 됩니다. 즉, session_starts 테이블 내의 date 고유값 개수가 365개라면, 각 rolling_mau 칼럼의 값을 계산하기 위해서는 동일한 테이블을 365번이나 메모리에 올려야 하는 것이죠.
WITH
CTE_rolling_mau AS (
SELECT
MAIN.date,
(
SELECT
COUNT(DISTINCT user_id)
FROM
session_starts SUB
WHERE
DATE_ADD('DAY', -29, MAIN.date) <= SUB.date
AND SUB.date <= MAIN.date
) AS rolling_mau
FROM
session_starts MAIN
GROUP BY
1
ORDER BY
1
)
SELECT
*
FROM
CTE_rolling_mau
;
결국, 30일 이동평균선과 달리 Rolling MAU의 경우 단순한 집계로 가능한 영역이 아니라, COUNT(DISTINCT user_id)를 수행하기 위한 테이블 재탐색이 각 Row마다 중복 발생해야 하는 영역입니다. 따라서 이는 쿼리문의 성능과 비용 관리에 매우 부정적인 영향을 끼치게 됩니다.
3. Static MAU
Static MAU는 제가 직접 마음대로 지어본 용어인데요. 😅 Rolling MAU에서 겪은 문제점에 대해 다음과 같은 방식으로 타협을 해봤습니다.

“어쩔 수 없네. 그럼, MAU는 Rolling 방식이 아닌 각 월 별로 Static하게 집계해보자!”
WITH
CTE_static_mau AS (
SELECT
DATE_TRUNC('MONTH', date) AS month,
COUNT(DISTINCT user_id) AS static_mau
FROM
session_starts
GROUP BY
1
ORDER BY
1
)
SELECT
*
FROM
CTE_static_mau
;
Static MAU는 Rolling MAU에 비해 다음과 같은 장/단점이 존재할 것 같습니다.
- 장점: 쿼리 비용이 크게 절감되고 연산 속도가 빨라집니다.
- 단점: 쿼리가 실행되는 시점 당월의 경우, 월말이 도래하기 전까지는 MAU가 과소평가되어 데이터 분석의 Freshness가 저하됩니다. 즉, 오늘이 1월 2일이라면 1월의 MAU는 1월 1일부터 1월 2일까지만 집계되겠죠.
4. Stickiness 지표
한편, 흔히 DAU➗MAU로 표현되는 Stickiness(사용자 고착도)를 측정하는 경우에는 Static과 Rolling 방식 사이의 고민이 더욱 깊어지게 됩니다.
Stickiness 지표는 토스, Instagram, YouTube, TikTok, 블라인드 등 활성 사용자들이 습관적으로 앱에 방문함으로써 광고 노출 효과 등을 극대화해야 하는 서비스에서 매우 중요한 지표입니다. 나쁘게 말하면, 사용자의 중독도를 파악하기 위한 지표인 것이죠. 😂

5. Rolling Stickiness
Stickiness도 마찬가지로, Rolling Stickiness와 Static Stickiness로 구분하여 연산할 수 있는데요. (Static Stickiness도 제가 마음대로 지어본 용어입니다.) 먼저 Rolling Stickiness 지표 산출을 위한 쿼리문은 다음과 같습니다.
(참고로, 분모가 0이 되는 케이스의 경우, 0으로 반환되도록 COALSECE(TRY(…), 0) 함수를 사용했습니다. 혼동이 없으시길 바랄게요! 🙃)
이 경우 Rolling MAU 연산 방식과 마찬가지로, Outer Table의 각 date마다 일일이 Inner Table의 모든 user_id 고유값 개수를 COUNT하게 됩니다. 즉, 메모리 사용량과 트래픽 수준이 급격하게 상승할 것입니다.
WITH
CTE_rolling_stickiness AS (
SELECT
MAIN.date,
COALESCE(
TRY(
COUNT(DISTINCT user_id)
/
(
SELECT
COUNT(DISTINCT user_id)
FROM
session_start SUB
WHERE
DATE_ADD('DAY', -29, MAIN.date) <= SUB.date
AND SUB.date <= MAIN.date
)
),
0
) AS rolling_stickiness
FROM
session_starts MAIN
GROUP BY
1
ORDER BY
1
)
SELECT
*
FROM
CTE_rolling_stickiness
;
6. Static Stickiness
그러나 Static Stickiness 방식으로 접근할 경우 쿼리문은 다음과 같습니다. DAU와 Static MAU를 Inline View로 먼저 계산한 후, 각 일자 별 dau를 고정된 월의 mau로 나누어주는 방식입니다. 이 경우, 쿼리 비용과 연산 속도를 크게 개선할 수 있게 됩니다.
WITH
CTE_dau AS (
SELECT
date,
COUNT(DISTINCT user_id) AS dau
FROM
session_starts
GROUP BY
1
),
CTE_static_mau AS (
SELECT
DATE_TRUNC('MONTH', date) AS month,
COUNT(DISTINCT user_id) AS static_mau
FROM
session_starts
GROUP BY
1
),
CTE_static_stickiness AS (
SELECT
dau.date,
COALESCE(
TRY(dau.dau / static_mau.static_mau),
0
) AS static_stickiness
FROM
dau
LEFT JOIN
static_mau
ON DATE_TRUNC('MONTH', dau.date) = static_mau.month
ORDER BY
1
)
SELECT
*
FROM
CTE_static_stickiness
;
물론, Static Stickiness는 Rolling Stickiness에 비해 다음과 같은 장/단점이 존재합니다.
- 장점: 쿼리 비용이 크게 절감되고 연산 속도가 빨라집니다.
- 단점: 당월의 경우, 월말이 도래하기 전까지는 MAU가 과소평가되어 Stickiness가 비정상적으로 높은 값으로 측정됩니다. 즉, 오늘이 1월 1일이라면,
DAU=MAU이므로Stickiness=100%인 말도 안되는 수치가 대시보드에 표시될 것입니다.😨
Stickiness=100% 로 표현되면, 사내 구성원들에게 잘못된 의사결정의 근거를 전달하게 될 위험성이 존재합니다. 따라서, Static Stickiness 방식을 사내에 도입하게 될 경우, 매월 초 자정에만 Appending되도록 하는 스케줄링을 두어야 할 것입니다. 즉, 1월 1일부터 1월 31일까지의 Stickiness 지표는 2월 1일이 되어야만 대시보드에 표현되는 것이죠. 그렇다면, Stickiness 지표는 최대 30일 이상 지연되어 서비스의 신속한 Action Item을 실행하기가 어려워질 것입니다. Stickiness는 Data Freshness가 중요한 지표 중 하나인데도 불구하고 말이죠.
7. Data Mart를 통해 Rolling MAU 도입하기
그러면 대안이 없을까요? 없으면 제가 이 글을 안 썼겠죠.🤭 Data Mart 내에 Incremental Strategy를 적용한 rolling_mau 테이블 스케줄링을 구축한다면 앞서 언급한 Rolling Stickiness의 치명적인 단점을 개선할 수 있습니다. 가령, 다음과 같이 매일 자정에 Appending되는 fact_rolling_mau 테이블을 생성한다고 가정해보겠습니다.
WITH
fact_rolling_mau AS (
SELECT
DATE_ADD('DAY', -1, CURRENT_DATE) AS date,
COUNT(DISTINCT user_id) AS rolling_mau
FROM
session_starts
WHERE
DATE_ADD('DAY', -30, CURRENT_DATE) <= date
AND date <= DATE_ADD('DAY', -1, CURRENT_DATE)
)
SELECT
*
FROM
fact_rolling_mau
;
즉 다음과 같이, fact_rolling_mau 테이블은 중복 연산 문제를 벗어난 채 매일 새로운 rolling_mau 값을 업데이트하게 됩니다.
| date | rolling_mau |
|---|---|
| 2023-01-01 | 100,000 |
| 2023-01-01 | 101,000 |
| … | … |
| 2023-01-01 | 99,700 |
| 2023-01-01 | 110,000 |
| … | … |
이제 이미 생성된 fact_rolling_mau 테이블을 통해 Rolling Stickiness를 계산하는 쿼리문을 작성하면 다음과 같습니다.
WITH
CTE_dau AS (
SELECT
date,
COUNT(DISTINCT user_id) AS dau
FROM
session_starts
GROUP BY
1
),
CTE_rolling_stickiness AS (
SELECT
dau.date,
COALESCE(
TRY(dau.dau / fact_rolling_mau.rolling_mau),
0
) AS rolling_stickiness
FROM
CTE_dau
LEFT JOIN
fact_rolling_mau
ON dau.date = rolling_mau.date
ORDER BY
1
)
SELECT
*
FROM
CTE_rolling_stickiness
;
8. 결론: Query Cost vs Data Freshness
결국 Rolling MAU, Rolling Stickiness 지표에 대한 이야기를 다루다보니 자연스럽게 Data Mart의 필요성으로 귀결되는 것 같습니다. Data Mart는 단순히 쿼리 결과의 정확성이나 일관성만을 위해 필요한 것이 아니라, 이처럼 Query Cost vs Data Freshness 사이의 상충 관계를 극복하기 위해서도 필요하다고 할 수 있습니다. 특히, 서비스의 사용 규모에 따라 소스 테이블의 사이즈가 방대해질수록 Data Mart의 활용은 필수적일 것입니다. 부족한 글을 읽어주셔서 감사합니다!
Published by Joshua Kim
