
Rolling MAU 쿼리 최적화
“Rolling MAU와 같은 복잡한 Rolling Metrics를 계산하는 데는 대규모 데이터셋에서 막대한 시간과 비용이 소요될 수 있습니다. 기존 쿼리로 6시간 이상 걸리던 작업을 쿼리 최적화와 B-tree Index를 통해 6초로 단축했습니다. 이 과정에서 불필요한 메모리 사용을 줄이고 쿼리 성능을 극대화하여 데이터 처리 효율성을 크게 향상시켰습니다. 이를 통해 기업이 Rolling MAU 지표를 효율적으로 관리하고 인프라 비용을 절감하는 데 기여할 수 있었습니다.”
| Performance Summary |
|---|
- 쿼리 실행 시간: 6시간→ 6초 |
목차
- STAR Summary
- Situation
- Tasks
- Actions
- Results
1. STAR Summary
Situation
- 회사는 Rolling MAU와 같은 복잡한 Rolling Metrics를 계산하고 관리하는 데 막대한 비용과 시간을 소모하고 있었습니다. 특히, 사용자가 많아질수록 이 지표를 효율적으로 추출하는 것이 더욱 어려워질 것으로 예상되었으며, 실제로 기존 쿼리로는 Rolling MAU를 계산하는 데 6시간 이상 소요되었습니다. Incremental Strategy를 적용하더라도 2시간이 걸리는 상황이었습니다.
Tasks
- 저는 Rolling MAU 지표를 효율적으로 계산할 수 있는 쿼리를 설계하여 실행 시간을 획기적으로 줄이고 인프라 비용을 절감하는 것을 목표로 삼았습니다. 이를 위해 쿼리 최적화를 통해 연산 비용을 낮추고 성능을 향상시키는 것이 필요했습니다.
Actions
- B-tree Index 생성
- Rolling MAU를 계산할 때 가장 많은 시간이 소요되는
date칼럼에 B-tree Index를 생성하여 스캔 속도를 향상시키고자 했습니다. 이를 통해 아래 조건에서 비교 연산의 부담을 줄이고자 한 것입니다.SUB.date BETWEEN MAIN.date - INTERVAL '29 DAYS' AND MAIN.date
- Rolling MAU를 계산할 때 가장 많은 시간이 소요되는
- 쿼리 최적화
- B-tree Index 생성 이후에도 성능 개선이 충분하지 않았습니다. 이에 따라 메모리 사용량을 줄이기 위해 쿼리에서 필요한 컬럼만 불러오는 방식으로 변경했습니다. MAIN 테이블에서 모든 행을 불러오는 대신, 아래와 같이 필요한 칼럼만 불러와 SELF JOIN 과정에서 기하급수적인 메모리 사용량을 대폭 줄였습니다.
SELECT DISTINCT date FROM daily_activated_users
- B-tree Index 생성 이후에도 성능 개선이 충분하지 않았습니다. 이에 따라 메모리 사용량을 줄이기 위해 쿼리에서 필요한 컬럼만 불러오는 방식으로 변경했습니다. MAIN 테이블에서 모든 행을 불러오는 대신, 아래와 같이 필요한 칼럼만 불러와 SELF JOIN 과정에서 기하급수적인 메모리 사용량을 대폭 줄였습니다.
Results
- 이 최적화 전략 덕분에 Rolling MAU 계산 쿼리의 실행 시간이 6시간에서 6초로 대폭 단축되었습니다. 이로 인해 데이터 처리 효율성이 극적으로 향상되었고, 쿼리 실행 시간과 인프라 비용 측면에서도 큰 절감 효과를 얻을 수 있었습니다. 이러한 성과는 기업이 Rolling Metrics와 같은 복잡한 지표를 보다 효율적으로 관리할 수 있도록 도왔습니다.
2. Situation
- 회사는 Rolling MAU와 같은 복잡한 Rolling Metrics를 계산하고 관리하는 데 막대한 비용과 시간을 소모하고 있었습니다. 특히, 사용자가 많아질수록 이 지표를 효율적으로 추출하는 것이 더욱 어려워질 것으로 예상되었으며, 실제로 기존 쿼리로는 Rolling MAU를 계산하는 데 6시간 이상 소요되었습니다. Incremental Strategy를 적용하더라도 2시간이 걸리는 상황이었습니다.
구체적인 문제 상황
- 회사가 운영하는 프로덕트는 시간이 지남에 따라 사용자 수가 급증하고 있었으며, 데이터 웨어하우스 관점에서 최적화가 중요한 이슈로 떠오르고 있었습니다. 특히, Rolling MAU는 프로덕트 요금제의 기준으로 필수적인 지표 역할을 했습니다. 그러나 Rolling MAU의 계산 과정은 매우 복잡하고 연산 비용이 높아 큰 고민이 되었습니다.
기존 쿼리 분석 및 병목 지점 파악
(1) 기존 쿼리
- 초기에 작성된 쿼리는 각 날짜별로 최근 30일 동안의 활성 사용자 수를 계산하기 위해 SELF JOIN을 사용했습니다. 이 방식은 모든 날짜에 대해 연관된 데이터를 반복적으로 조회하고 계산하는 과정에서 O(n²)의 연산 복잡도를 가지며, 사용자가 많아질수록 연산 비용이 기하급수적으로 증가하는 문제점을 지니고 있었습니다. 실제로, 이 쿼리를 Full Scan으로 실행할 때 6시간 이상 소요되었으며, Incremental Strategy로 실행해도 2시간 가까이 걸렸습니다.
SELECT MAIN.date, COUNT(DISTINCT SUB.user_id) AS rolling_mau FROM daily_activated_users MAIN LEFT JOIN daily_activated_users SUB ON SUB.date BETWEEN MAIN.date - INTERVAL '29 DAYS' AND MAIN.date GROUP BY MAIN.date ORDER BY MAIN.date
(2) 기존 쿼리 분석 (Rolling 2-day Active Users 사례)
- A. 먼저, 아래 과정을 통해
daily_activated_users테이블의 데이터를 가져옵니다.자세히 보기
FROM daily_activated_users MAIN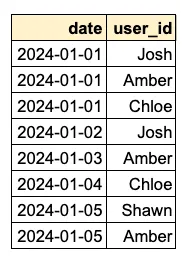
- B. 그런 후, SELF JOIN을 통해 각 일별 Recent 2-day 활성 사용자 목록을 모두 이어 붙입니다.
자세히 보기
FROM daily_activated_users MAIN LEFT JOIN daily_activated_users SUB ON SUB.date BETWEEN MAIN.date - INTERVAL '1 DAYS' AND MAIN.date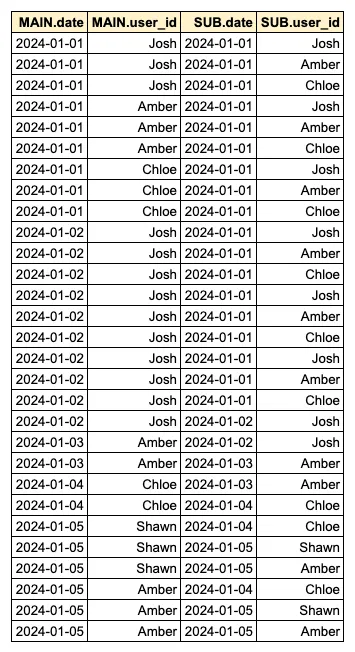
- C. 이제
MAIN.date를 기준으로 그룹화하여 순수 사용자 수를 계산합니다.자세히 보기
SELECT MAIN.date, COUNT(DISTINCT SUB.user_id) AS rolling_mau FROM daily_activated_users MAIN LEFT JOIN daily_activated_users SUB ON SUB.date BETWEEN MAIN.date - INTERVAL '29 DAYS' AND MAIN.date GROUP BY MAIN.date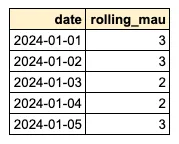
- 정확한 병목 지점 파악
- 연산 시간이 가장 많이 소모되는 지점은 단계 B입니다. 이 단계에서는 각 행마다 Recent 2-day Window에 해당하는 모든 행을 이어 붙이는 과정이 이루어집니다. 예를 들어, 1월 2일의 행 수가 10개이고, Recent 2-day Window에 해당하는 행이 100개라면, 총 1,000개의 행(10*100)을 이어 붙여야 하므로 메모리 사용량이 급격히 증가합니다. 즉, SELF JOIN을 통해 각 일별 Recent 2-day 활성 사용자 목록을 이어 붙이는 과정이 Scan 시간과 메모리 사용량을 상당히 많이 소모하는 원인이었습니다.
- 이러한 상황에서, Rolling MAU 지표를 보다 효율적으로 개선하고 쿼리 실행 시간을 대폭 줄이기 위한 최적화가 시급한 과제로 떠올랐습니다. 또한, 기존 인프라로는 이와 같은 연산 비용을 지속적으로 감당하는 것이 비효율적이었기 때문에, 최적화를 통해 인프라 비용도 절감할 필요가 있었습니다. 즉, 비용과 시간을 절감할 수 있는 솔루션을 찾는 것이 절실한 상황이었습니다.
3. Tasks
- 저는 Rolling MAU 지표를 효율적으로 계산할 수 있는 쿼리를 설계하여 실행 시간을 획기적으로 줄이고 인프라 비용을 절감하는 것을 목표로 삼았습니다. 이를 위해 쿼리 최적화를 통해 연산 비용을 낮추고 성능을 향상시키는 것이 필요했습니다.
1. 쿼리 실행 시간 단축
- Rolling MAU를 계산하는 기존 쿼리는 O(n²)의 연산 복잡도를 가지고 있었기 때문에, 실행 시간이 6시간 이상 걸렸습니다. 이를 크게 단축하여 실시간 분석에 가까운 성능을 구현하는 것이 최우선 과제였습니다. 실행 시간을 초 단위로 줄여야만, 빠르게 변화하는 사용자 활동 데이터를 분석하고 즉각적으로 대응할 수 있는 환경을 마련할 수 있었습니다.
2. 인프라 비용 절감
- 쿼리 실행 시 사용되는 메모리와 처리 능력은 비용으로 직결됩니다. 기존 쿼리는 데이터 양이 증가함에 따라 메모리 사용량도 기하급수적으로 늘어나고, 이로 인해 인프라 비용이 급증하는 문제가 있었습니다. 따라서, 메모리 사용량을 줄이고 인프라 자원을 효율적으로 활용할 수 있는 쿼리 구조를 설계하는 것이 필요했습니다.
4. Actions
- B-tree Index 생성
- Rolling MAU를 계산할 때 가장 많은 시간이 소요되는
date칼럼에 B-tree Index를 생성하여 스캔 속도를 향상시키고자 했습니다. 이를 통해 아래 조건에서 비교 연산의 부담을 줄이고자 한 것입니다.SUB.date BETWEEN MAIN.date - INTERVAL '29 DAYS' AND MAIN.date- 쿼리 최적화
- B-tree Index 생성 이후에도 성능 개선이 충분하지 않았습니다. 이에 따라 메모리 사용량을 줄이기 위해 쿼리에서 필요한 컬럼만 불러오는 방식으로 변경했습니다. MAIN 테이블에서 모든 행을 불러오는 대신, 아래와 같이 필요한 칼럼만 불러와 SELF JOIN 과정에서 기하급수적인 메모리 사용량을 대폭 줄였습니다.
SELECT DISTINCT date FROM daily_activated_users
1. B-tree Index 생성
- 병목 지점이었던
date칼럼 비교 연산의 성능을 향상시키기 위해,date칼럼에 B-tree Index를 생성했습니다.CREATE INDEX idx_dates ON daily_activated_users USING btree (date); - 이를 통해, 아래의
date검색 속도를 개선하여 쿼리 시간이 소폭 개선되었으나, 여전히 메모리 사용량과 실행 시간이 과도하게 많이 소요되고 있었습니다.FROM daily_activated_users MAIN LEFT JOIN daily_activated_users SUB ON SUB.date BETWEEN MAIN.date - INTERVAL '29 DAYS' AND MAIN.date
2. 쿼리 최적화
- 안타깝게도
date칼럼을 Index로 생성했음에도 불구하고 쿼리 실행 시간은 여전히 과도하게 많이 소요되고 있었습니다. - 즉, 핵심 문제는
date칼럼 비교 연산 과정이라기보다는, SELF JOIN 과정의 기하급수적인 메모리 사용 과정이었던 것입니다. 따라서 메모리 사용량을 줄이기 위해 반드시 필요한 칼럼만을 불러오는 방법을 고안했습니다.SELECT MAIN.date, COUNT(DISTINCT SUB.user_id) AS rolling_mau FROM (SELECT DISTINCT date FROM daily_activated_users) MAIN -- 변경한 부분 LEFT JOIN daily_activated_users SUB ON SUB.date BETWEEN MAIN.date - INTERVAL '29 DAYS' AND MAIN.date GROUP BY MAIN.date - 이를 통해 SELF JOIN의 데이터 처리량을 드라마틱하게 줄여 메모리 사용량을 대폭 감소시켰습니다.
5. Results
- 이 최적화 전략 덕분에 Rolling MAU 계산 쿼리의 실행 시간이 6시간에서 6초로 대폭 단축되었습니다. 이로 인해 데이터 처리 효율성이 극적으로 향상되었고, 쿼리 실행 시간과 인프라 비용 측면에서도 큰 절감 효과를 얻을 수 있었습니다. 이러한 성과는 기업이 Rolling Metrics와 같은 복잡한 지표를 보다 효율적으로 관리할 수 있도록 도왔습니다.
쿼리 실행 시간의 극적 단축
- Rolling MAU는 프로덕트의 요금제 기준으로 기획되었기 때문에, 본 문제는 상당히 중요한 이슈였습니다.
- 최적화 이전: Rolling MAU를 계산하는 쿼리가 약 6시간 소요
- 최적화 이후: 동일한 작업이 단 6초 만에 완료
- 이렇게 단축된 실행 시간 덕분에 더욱 안정적인 프로덕트 운영이 가능해졌으며 요금제 기준의 대체 방법을 고민할 수도 있었던 기업의 기회비용을 절약할 수 있었습니다.
Published by Joshua Kim
