
Rolling MAU Query Optimization
2024-06-30
“Calculating complex Rolling Metrics like Rolling MAU can consume significant time and cost on large datasets. A task that previously took over 6 hours with the original query was reduced to 6 seconds through query optimization and the use of a B-tree Index. This process significantly enhanced data processing efficiency by minimizing unnecessary memory usage and maximizing query performance. As a result, the company was able to manage Rolling MAU metrics more efficiently, contributing to infrastructure cost savings.”
| Performance Summary |
|---|
- Query Execution Time: 6 hours→ 6 seconds |
Table of Contents
- STAR Summary
- Situation
- Tasks
- Actions
- Results
1. STAR Summary
Situation
- The company was consuming significant time and costs to calculate and manage complex Rolling Metrics like Rolling MAU. As the number of users increased, it was expected to become even more challenging to extract this metric efficiently, and indeed, the original query took more than 6 hours to calculate Rolling MAU. Even with an Incremental Strategy applied, it still took 2 hours.
Tasks
- My goal was to design a query that could calculate the Rolling MAU metric efficiently, drastically reduce execution time, and lower infrastructure costs. This required query optimization to reduce computational costs and improve performance.
Actions
- Creating a B-tree Index
- To speed up the most time-consuming process of calculating Rolling MAU, I created a B-tree Index on the
datecolumn to enhance scan speed. This was intended to reduce the burden of comparison operations under the following condition:SUB.date BETWEEN MAIN.date - INTERVAL '29 DAYS' AND MAIN.date
- To speed up the most time-consuming process of calculating Rolling MAU, I created a B-tree Index on the
- Query Optimization
- Even after creating the B-tree Index, the performance improvement was not sufficient. Therefore, I changed the query to fetch only the necessary columns to reduce memory usage. Instead of fetching all rows from the MAIN table, I fetched only the necessary columns, significantly reducing the exponential memory usage during the SELF JOIN process.
SELECT DISTINCT date FROM daily_activated_users
- Even after creating the B-tree Index, the performance improvement was not sufficient. Therefore, I changed the query to fetch only the necessary columns to reduce memory usage. Instead of fetching all rows from the MAIN table, I fetched only the necessary columns, significantly reducing the exponential memory usage during the SELF JOIN process.
Results
- Thanks to this optimization strategy, the execution time for the Rolling MAU calculation query was reduced from 6 hours to 6 seconds. This led to a dramatic improvement in data processing efficiency and significant cost savings in query execution time and infrastructure. These results helped the company manage complex metrics like Rolling Metrics more efficiently.
2. Situation
- The company was consuming significant time and costs to calculate and manage complex Rolling Metrics like Rolling MAU. As the number of users increased, it was expected to become even more challenging to extract this metric efficiently, and indeed, the original query took more than 6 hours to calculate Rolling MAU. Even with an Incremental Strategy applied, it still took 2 hours.
Specific Problem Situation
- The company’s product saw a rapid increase in users over time, making optimization a critical issue from a data warehouse perspective. The Rolling MAU, a key metric for product pricing, played an essential role. However, the calculation process for Rolling MAU was very complex and computationally expensive, which posed a significant challenge.
Analysis of the Existing Query and Identification of Bottlenecks
(1) The Existing Query
- The initial query used a SELF JOIN to calculate the number of active users over the last 30 days for each date. This approach had a computational complexity of O(n²) because it repeatedly retrieved and calculated related data for each date, causing an exponential increase in computation cost as the number of users grew. In practice, this query took more than 6 hours to execute with a Full Scan, and nearly 2 hours even with an Incremental Strategy.
SELECT MAIN.date, COUNT(DISTINCT SUB.user_id) AS rolling_mau FROM daily_activated_users MAIN LEFT JOIN daily_activated_users SUB ON SUB.date BETWEEN MAIN.date - INTERVAL '29 DAYS' AND MAIN.date GROUP BY MAIN.date ORDER BY MAIN.date
(2) Analysis of the Existing Query (Rolling 2-day Active Users Example)
- A. First, the
daily_activated_userstable data is retrieved through the following process:View code
FROM daily_activated_users MAIN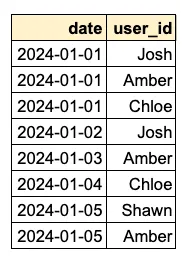
- B. Then, a SELF JOIN is performed to concatenate the list of active users for the recent 2-day period for each day.
View code
FROM daily_activated_users MAIN LEFT JOIN daily_activated_users SUB ON SUB.date BETWEEN MAIN.date - INTERVAL '1 DAYS' AND MAIN.date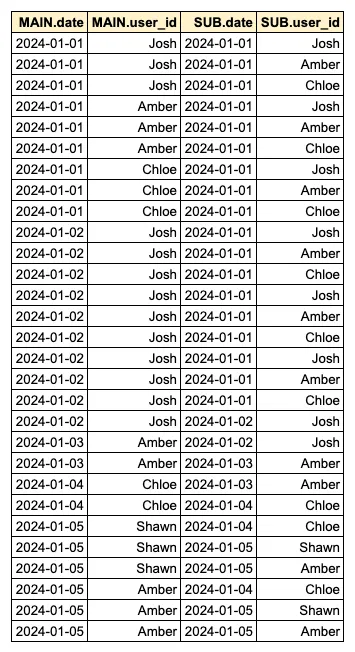
- C. Now, the users are grouped by
MAIN.dateto calculate the unique number of users.View code
SELECT MAIN.date, COUNT(DISTINCT SUB.user_id) AS rolling_mau FROM daily_activated_users MAIN LEFT JOIN daily_activated_users SUB ON SUB.date BETWEEN MAIN.date - INTERVAL '29 DAYS' AND MAIN.date GROUP BY MAIN.date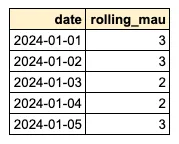
- Identifying the Exact Bottleneck
- The most time-consuming part is step B. In this step, all rows corresponding to the Recent 2-day Window are concatenated for each row. For example, if there are 10 rows on January 2nd, and 100 rows corresponding to the Recent 2-day Window, a total of 1,000 rows (10*100) need to be concatenated, resulting in a rapid increase in memory usage. The process of concatenating the list of active users for each day through SELF JOIN was the primary cause of excessive scan time and memory usage.
- Given this situation, it became urgent to optimize the Rolling MAU metric to improve efficiency and significantly reduce query execution time. Additionally, continuing to bear such computational costs with the existing infrastructure was inefficient, necessitating optimization to reduce infrastructure costs. In other words, finding a solution to save both time and costs was crucial.
3. Tasks
- My goal was to design a query that could calculate the Rolling MAU metric efficiently, drastically reduce execution time, and lower infrastructure costs. This required query optimization to reduce computational costs and improve performance.
1. Reducing Query Execution Time
- The original query for calculating Rolling MAU had a computational complexity of O(n²), resulting in an execution time of over 6 hours. Drastically reducing this time to achieve near real-time performance was the top priority. Reducing execution time to the second level was essential to quickly analyze changing user activity data and respond immediately.
2. Reducing Infrastructure Costs
- Memory and processing power used during query execution directly translate to costs. The original query had an issue where memory usage increased exponentially as the data volume grew, leading to a sharp rise in infrastructure costs. Therefore, it was necessary to design a query structure that minimized memory usage and efficiently utilized infrastructure resources.
4. Actions
- Creating a B-tree Index
- To speed up the most time-consuming process of calculating Rolling MAU, I created a B-tree Index on the
datecolumn to enhance scan speed. This was intended to reduce the burden of comparison operations under the following condition:SUB.date BETWEEN MAIN.date - INTERVAL '29 DAYS' AND MAIN.date- Query Optimization
- Even after creating the B-tree Index, the performance improvement was not sufficient. Therefore, I changed the query to fetch only the necessary columns to reduce memory usage. Instead of fetching all rows from the MAIN table, I fetched only the necessary columns, significantly reducing the exponential memory usage during the SELF JOIN process.
SELECT DISTINCT date FROM daily_activated_users
1. Creating a B-tree Index
- To improve the performance of comparison operations on the
datecolumn, which was the bottleneck, I created a B-tree Index on thedatecolumn.CREATE INDEX idx_dates ON daily_activated_users USING btree (date); - This improved the search speed for
dateand slightly reduced query time, but the memory usage and execution time were still excessively high.FROM daily_activated_users MAIN LEFT JOIN daily_activated_users SUB ON SUB.date BETWEEN MAIN.date - INTERVAL '29 DAYS' AND MAIN.date
2. Query Optimization
- Unfortunately, even after creating an index on the
datecolumn, the query execution time was still excessively high. - The core issue was not the comparison operations on the
datecolumn, but rather the exponential memory usage during the SELF JOIN process. To reduce memory usage, I devised a method to retrieve only the necessary columns.SELECT MAIN.date, COUNT(DISTINCT SUB.user_id) AS rolling_mau FROM (SELECT DISTINCT date FROM daily_activated_users) MAIN -- The Modified Part LEFT JOIN daily_activated_users SUB ON SUB.date BETWEEN MAIN.date - INTERVAL '29 DAYS' AND MAIN.date GROUP BY MAIN.date - This drastically reduced the data processing load during SELF JOIN, significantly decreasing memory usage.
5. Results
- Thanks to this optimization strategy, the execution time for the Rolling MAU calculation query was reduced from 6 hours to 6 seconds. This led to a dramatic improvement in data processing efficiency and significant cost savings in query execution time and infrastructure. These results helped the company manage complex metrics like Rolling Metrics more efficiently.
Dramatic Reduction in Query Execution Time
- Since Rolling MAU was a key metric for product pricing, this issue was of significant importance.
- Before Optimization: The query for calculating Rolling MAU took about 6 hours
- After Optimization: The same task was completed in just 6 seconds
- The reduced execution time enabled more stable product operations and saved the company from considering alternative pricing methods, thereby saving opportunity costs.
Published by Joshua Kim
