데이터 분석가의 SQL 최적화 일기: 코호트 리텐션 Batch Query 만들기
코호트 리텐션의 의미와 중요성에 대해 말씀드리고, Batch Query를 사용하여 회원가입 월 코호트 별로 Monthly Range Retention을 계산하는 방법을 제시해드릴게요.
CONTENTS
- 코호트 리텐션의 의미와 중요성
- 1.1. 리텐션
- 1.2. 코호트
- 1.3. 코호트 리텐션
- 1.4. 코호트 리텐션의 중요성
- 쿼리 작업 목표
- 일회성 쿼리문
- 3.1. 쿼리문 보기
- 3.2. 문제점
- 해결 아이디어
- Batch Query를 통해 접근하기
- 결론
DISCLAIMER
본 아티클은 필자의 전/현 재직 기업의 데이터 분석 현황과 관련이 없으며, 단지 평소에 문제 의식을 지녔던 점에 대한 해결 방법을 스스로 도출해본 내용입니다. 쿼리문 작성에 다른 외부 레퍼런스를 참고하지 않았으며, 분석 환경에 따라 본 내용이 적합하지 않을 수 있으므로 반드시 비판적 고찰을 해주시면 감사드리겠습니다.
1. 코호트 리텐션의 의미와 중요성
1.1. 리텐션
먼저, 리텐션은 “시간이 흐름에 따라 얼마나 많은 사용자들이 우리 프로덕트에 재참여하는지”를 나타내는 지표입니다. 이미 많은 분들이 아시듯 리텐션은 PMF를 달성하기 위해 분석해야 할 중요한 지표입니다. 이 정의가 꽤나 간단해보이지만, 측정하는 과정에서 실상은 그렇지 않습니다. “재참여”를 “재”와 “참여”로 나누어 각각의 사전 정의가 이루어져야 하기 때문입니다.
“참여” 개념 정의하기
사용자가 우리 프로덕트에 “참여”한다는 것이 정확히 어떤 순간인지 정의해야 합니다. 예를 들어, 접속, 30초 이상 세션 유지, 특정 퍼널 단계 도달 등 여러 이벤트 중 하나가 “참여”로 간주될 수 있습니다. 저는 개인적으로 아래 3가지 측면 정의를 모두 사전에 준비하여 Target Metric에 따라 적시적소에 모니터링하는 것이 필요하다고 느꼈습니다.
(1) “접속”을 하는 것만으로 참여한 것으로 간주하자!
- DAU, WAU, MAU, Stickiness 등의 지표와 직접적으로 연관된 정의 방법이며, 광고 노출 효과를 극대화하는 경우 유용합니다.
(2) “구매”까지 해야 참여한 것으로 간주하자!
- 재구매율 등의 지표와 직접적으로 연관된 정의 방법이며, Recurring Revenue가 중요한 프로덕트에서 중요합니다.
(3) “아하 모먼트”에 도달해야 참여한 것으로 간주하자!
- 토스의 이승건 대표님에 따르면, 아하 모먼트란 프로덕트의 핵심 가치의 경험하는 순간을 의미합니다.
- X, Y, Z의 조합으로 이루어진 여러 가지 “X 이벤트를 Y 기간 내에 Z번 수행한다” 중 리텐션이 극명하게 높은(가령, 95%) 항목을 사전에 발견하여, 빠르게 PMF를 달성해야 할 때 유용합니다.
“재” 개념 정의하기
사용자가 복귀했다는 것을 어떻게 계산할 것인가에 대한 정의가 필요합니다. 양승화님의 그로스해킹에 따르면, Classic Retention, Range Retention, Rolling Retention 중 프로덕트의 특성에 따라 적절한 방법을 선택할 수 있습니다.
(1) Classic Retention: 사용자가 최초로 “참여”한 Day 0 이후, 각 Day N 별로 한 번 더 “참여”했는지 계산합니다.
(2) Range Retention: Day N이 아니라 Week N, Bi-week N, Month N 별로 한 번 더 “참여”했는지 계산합니다.
(3) Rolling Retention: Day N 이후에 한 번이라도 “참여”한 경우를 계산합니다. (이탈률의 반대 개념)
이러한 정의와 측정 방법을 통해 효과적인 리텐션 지표 측정이 가능해질 것입니다.
1.2. 코호트
코호트의 개념을 두 가지로 혼용하는 경향이 있습니다.
- “코호트는 세그먼트다. 즉, 사용자가 지닌 여러 가지 Feature 조합을 통해 그룹화된 클러스터다.”
- “코호트는 세그먼트의 일부로서, 특정 이벤트의 최초 수행일시를 기준으로 그룹화된 클러스터다.” (최초 프로덕트 방문일, 회원가입일, 최초 결제일 등)
개인적으로는 세그먼트와의 혼동을 줄이기 위해 2번의 개념을 선호하지만, 코호트를 융통성 있게 설정하기 위해 1번 개념에서 언급한 다른 Feature 조합도 선택적으로 추가할 수 있는 “열린 개념”으로 받아들이고 있습니다.
- 예시 1) 사용자를 최초 프로덕트 방문일 기준으로 그룹화한다. → 코호트 O
- 예시 2) 사용자를 최초 접속 국가 기준으로 그룹화한다. → 코호트 X
- 예시 3) 사용자를 최초 프로덕트 방문일 및 접속 국가 기준으로 그룹화한다. → 코호트 O
이렇게 하면 특정 이벤트의 최초 수행일시를 중심으로 하면서도 다양한 특성을 고려할 수 있어서 코호트를 보다 유연하게 활용할 수 있을 것입니다.
1.3. 코호트 리텐션
코호트 리텐션이란, 기존의 리텐션 개념을 코호트에 따라 시리즈를 달리하여 계산한 지표를 의미합니다. 예를 들면, 최초 프로덕트 방문일을 기준으로 사용자들의 리텐션이 상승 추세인지, 혹은 하락 추세인지를 알 수 있는 것이죠.
1.4. 코호트 리텐션의 중요성
아래의 리텐션 지표를 통해 PMF 달성 여부를 확인할 수 있지만, 문제를 파악하거나 액션 포인트를 도출하는 데는 그다지 도움이 되지 않습니다.
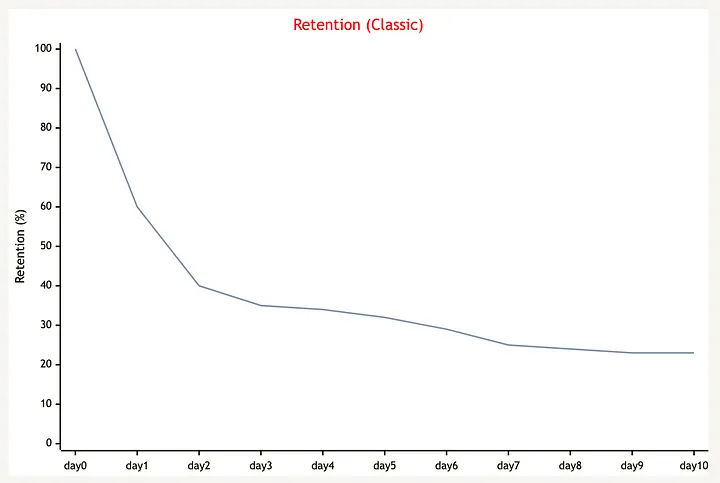
mermaid를 통해 필자가 직접 작성
그러나 코호트 리텐션 값을 확인할 수 있다면, 프로덕트의 기능 업데이트나 캠페인 론칭 등에 따른 사후 효과를 확인하고, 리텐션 향상을 위해 우리가 어떤 액션에 좀 더 집중해야 하는지 확인하는 데 도움을 줄 수 있습니다.
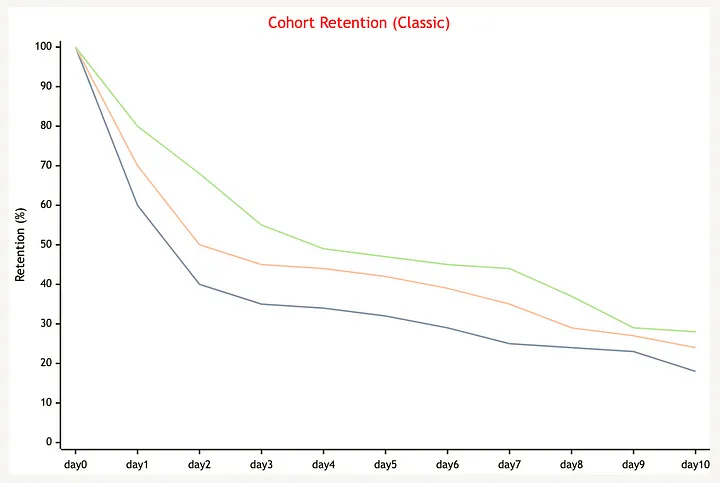
mermaid를 통해 필자가 직접 작성
2. 쿼리 작업 목표
쿼리 작업 목표는 다음과 같습니다. 아래와 같은 테이블을 대시보드에 반영해보고자 합니다. 즉, 회원가입 연월(YYYY-MM) 코호트별 리텐션(Monthly Range)테이블을 배포하여 다양한 이해당사자 분들이 리텐션 지표의 시계열 추이를 확인하시는 데 도움을 드리려는 것입니다.
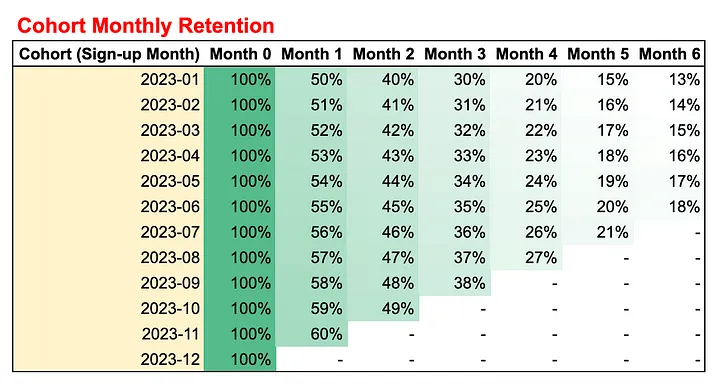
제가 직접 샘플로 만들어본 위 테이블에서는 시간이 흐를수록 리텐션이 향상되는 추이를 보여주고 있군요.
그런데, 위와 같은 테이블을 만들기 위해서는 SQL의 최후 출력 상태가 다음과 같은 Unpivoted한 형태가 되어야 합니다. 물론 Pivoted한 형태로 직접 출력하는 방법도 있지만, 오늘의 토픽인 “Batch Query 만들기”를 위해서는 Unpivoted한 형태가 되어야 합니다. Table을 Update를 방지하고, 오로지 Insert 작업만 수행함으로써 연산 부하를 방지하기 위함인데요. 지금부터 차차 읽어가시면 이해가 되실 겁니다.
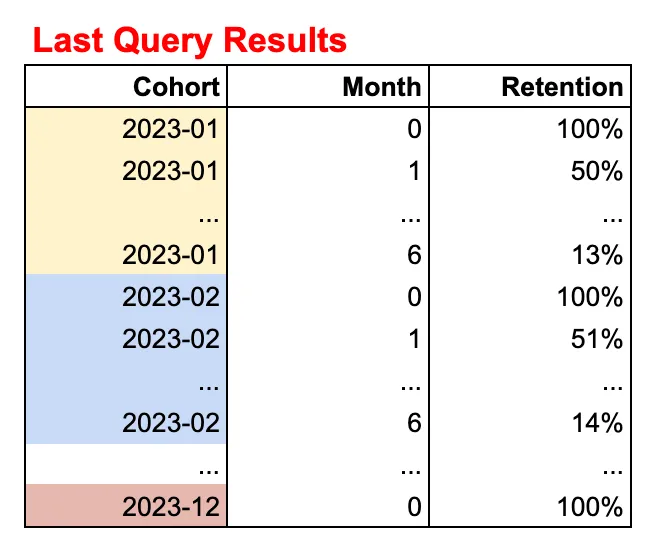
필자가 직접 작성
3. 일회성 쿼리문
3.1. 쿼리문 보기
WITH
-- 1. 사용자들의 "참여" (회원가입 및 로그인 이벤트) 소스 테이블을 불러온다.
CTE_engagements AS (
SELECT
user_id,
DATE_TRUNC('DAY', datetime) AS date
FROM
signups_logins
GROUP BY
1, 2
),
-- 2. 사용자들을 회원가입일 기준의 코호트로 Labeling해준다.
CTE_cohorts AS (
SELECT
user_id,
MIN(date) AS cohort_date
FROM
CTE_engagements
GROUP BY
1
),
-- 3. 사용자들의 "참여" 테이블과 "코호트 Labeling" 테이블을 조인하여 "Day N"도 함께 표시해준다.
CTE_engagements_with_cohorts_daily AS (
SELECT
ENG.user_id,
ENG.date,
COH.cohort_date,
DATE_DIFF(
ENG.date,
COH.cohort_date,
DAY
) AS day_n
FROM
CTE_engagements ENG
LEFT JOIN
CTE_cohorts COH
USING (user_id)
),
-- 4. "Day N"을 "Month N"으로 변환해준다.
CTE_engagements_with_cohorts_monthly AS (
SELECT
user_id,
DATE_TRUNC('MONTH', date) AS yyyymm,
DATE_TRUNC('MONTH', cohort_date) AS cohort_yyyymm,
DATE_DIFF(
date,
cohort_date,
MONTH
) AS month_n
FROM
CTE_engagements_with_cohorts_daily
),
-- 5. 코호트 및 "Month N" 기준으로 사용자 수를 집계한다.
CTE_month_n_cnt AS (
SELECT
cohort_yyyymm,
month_n,
COUNT(DISTINCT user_id) AS users_cnt
FROM
CTE_engagements_with_cohorts_monthly
GROUP BY
1, 2
),
-- 6. 최종 리텐션을 계산한다.
CTE_monthly_retention AS (
SELECT
cohort_yyyymm,
month_n,
CAST(users_cnt AS DOUBLE)
/
CAST(FIRST_VALUE(users_cnt) OVER (
PARTITION BY cohort_yyyymm
ORDER BY month_n
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
) AS DOUBLE
) AS monthly_retention
FROM
CTE_month_n_cnt
ORDER BY
1, 2
)
SELECT
*
FROM
CTE_monthly_retention
;
3.2. 문제점
위 쿼리문의 출력 결과는 앞서 잠깐 보여드린 아래와 같은 형태의 테이블을 출력합니다. 그런데, 매번 전체 소스 테이블을 메모리에 올려 리텐션을 계산하려면 연산량이 과도하게 많이 들어 리소스 낭비로 이어지게 됩니다.
필자가 직접 작성
4. 해결 아이디어
마침, Cohort 칼럼과 Month 칼럼이 시계열 형식을 지니고 있으므로 미래의 데이터가 과거의 데이터에 영향을 끼칠 수 없습니다. 또한, 출력된 테이블은 Periodic Snapshot Fact Table의 유형에 해당합니다. 바로 이 점으로부터 우리는 Batch Query를 활용할 수 있는 여지를 발견할 수 있습니다. 즉, 아래와 같이 매월 1일 00:01 UTC마다 새롭게 획득한 리텐션 값들을 Insert할 수 있는 Batch Query를 작성할 수 있는 것입니다. 특히 이벤트 로그 데이터의 크기가 매우 큰 프로덕트를 운영하고 있다면, 굳이 매번 일회성 쿼리문을 실행할 필요가 없는 셈이죠.
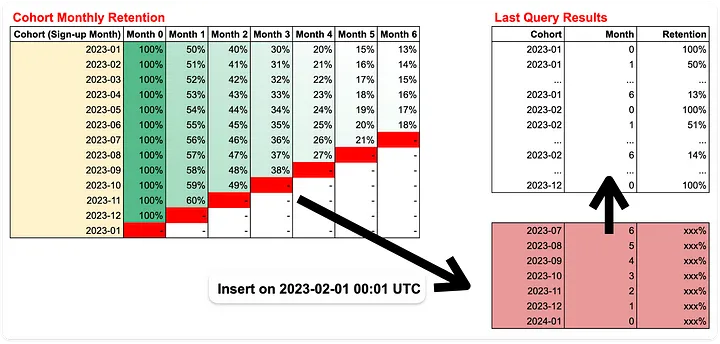
즉, 매월 초마다 좌측 테이블의 빨간색 영역들을 순차적으로 신규 계산하여 테이블 Insert 스케줄링을 구현할 수 있는 것이죠. (필자가 직접 작성)
5. Batch Query를 통해 접근하기
STEP 1) 사용자들의 “참여” 소스 테이블을 불러온다. (단, 현재 시점 기준으로 7개월 전의 월초부터 1개월 전의 월말까지 항목만)
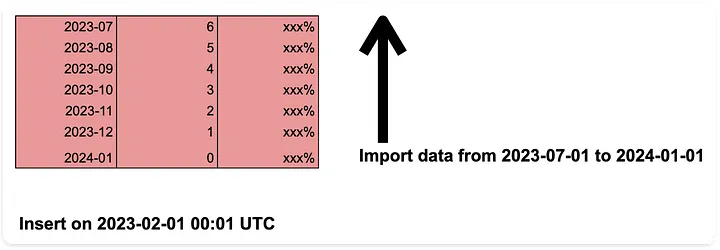
필자가 직접 작성
- 로그인했을 때 사용자가 “참여”했다고 가정 하에, 로그인 이벤트를 불러온다.
- 코호트는 “회원가입” 기준으로 정의할 것이므로, 회원가입 이벤트도 함께 불러온다.
- Monthly Range Retention은 Month 0부터 Month 6까지만 계산한다.
WITH
-- 1. 사용자들의 "참여" (회원가입 및 로그인 이벤트) 소스 테이블을 불러온다.
-- (단, 현재 시점 기준으로 7개월 전의 월초부터 1개월 전의 월말까지 항목만)
CTE_engagements AS (
SELECT
user_id,
DATE_TRUNC('DAY', datetime) AS date
FROM
source.signups_logins
"if is_incremental()"
WHERE
-- 현재 시점 기준으로 7개월 전의 월초부터 ~
DATE_TRUNC('MONTH', CURRENT_DATE) - INTERVAL '7' MONTH
<= DATE_TRUNC('DAY', datetime)
-- ~ 현재 시점 기준으로 1개월 전의 월말까지
AND DATE_TRUNC('DAY', datetime)
<= DATE_TRUNC('MONTH', CURRENT_DATE) - INTERVAL '1' DAY
"endif"
GROUP BY
1, 2
),
STEP 2) 사용자들을 회원가입일 기준의 코호트로 Labeling해준다.
-- 2. 사용자들을 회원가입일 기준의 코호트로 Labeling해준다.
CTE_cohorts AS (
SELECT
user_id,
MIN(date) AS cohort_date
FROM
CTE_engagements
GROUP BY
1
),
STEP 3) 사용자들의 “참여” 테이블과 “코호트 Labeling” 테이블을 조인하여 “Day N”도 함께 표시해준다.
-- 3. 사용자들의 "참여" 테이블과 "코호트 Labeling" 테이블을 조인하여 "Day N"도 함께 표시해준다.
CTE_engagements_with_cohorts_daily AS (
SELECT
ENG.user_id,
ENG.date,
COH.cohort_date,
DATE_DIFF(
ENG.date,
COH.cohort_date,
DAY
) AS day_n
FROM
CTE_engagements ENG
LEFT JOIN
CTE_cohorts COH
USING (user_id)
),
STEP 4) “Day N”을 “Month N”으로 변환해준다.
- Monthly Range Retention을 계산해야 하기 때문이다.
-- 4. "Day N"을 "Month N"으로 변환해준다.
CTE_engagements_with_cohorts_monthly AS (
SELECT
user_id,
DATE_TRUNC('MONTH', date) AS yyyymm,
DATE_TRUNC('MONTH', cohort_date) AS cohort_yyyymm,
DATE_DIFF(
date,
cohort_date,
MONTH
) AS month_n
FROM
CTE_engagements_with_cohorts_daily
),
STEP 5) 코호트 및 “Month N” 기준으로 사용자 수를 집계한다.
-- 5. 코호트 및 "Month N" 기준으로 사용자 수를 집계한다.
CTE_month_n_cnt AS (
SELECT
cohort_yyyymm,
month_n,
COUNT(DISTINCT user_id) AS users_cnt
FROM
CTE_engagements_with_cohorts_monthly
GROUP BY
1, 2
),
STEP 6) 최종 리텐션을 계산한다.
-- 6. 최종 리텐션을 계산한다.
CTE_monthly_retention AS (
SELECT
cohort_yyyymm,
month_n,
CAST(users_cnt AS DOUBLE)
/
CAST(FIRST_VALUE(users_cnt) OVER (
PARTITION BY cohort_yyyymm
ORDER BY month_n
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
)
AS monthly_retention
FROM
CTE_month_n_cnt
ORDER BY
1, 2
)
STEP 7) 중복되지 않은 신규 항목들만 Insert할 수 있도록 조건화한다.
필자가 직접 작성
-- 7. 중복되지 않은 신규 항목들만 Insert할 수 있도록 조건화한다.
CTE_monthly_retention_inserted AS (
SELECT
*
FROM
CTE_monthly_retention
"if is_incremental()"
WHERE
-- 현재 시점 기준으로 1개월 전의 코호트: Month 0 리텐션 값만 Insert한다.
(cohort_yyyymm = DATE_TRUNC('MONTH', CURRENT_DATE) - INTERVAL '1' MONTH AND month_n = 0)
-- 현재 시점 기준으로 2개월 전의 코호트: Month 1 리텐션 값만 Insert한다.
OR (cohort_yyyymm = DATE_TRUNC('MONTH', CURRENT_DATE) - INTERVAL '2' MONTH AND month_n = 1)
-- 현재 시점 기준으로 3개월 전의 코호트: Month 2 리텐션 값만 Insert한다.
OR (cohort_yyyymm = DATE_TRUNC('MONTH', CURRENT_DATE) - INTERVAL '3' MONTH AND month_n = 2)
-- 현재 시점 기준으로 4개월 전의 코호트: Month 3 리텐션 값만 Insert한다.
OR (cohort_yyyymm = DATE_TRUNC('MONTH', CURRENT_DATE) - INTERVAL '4' MONTH AND month_n = 3)
-- 현재 시점 기준으로 5개월 전의 코호트: Month 4 리텐션 값만 Insert한다.
OR (cohort_yyyymm = DATE_TRUNC('MONTH', CURRENT_DATE) - INTERVAL '5' MONTH AND month_n = 4)
-- 현재 시점 기준으로 6개월 전의 코호트: Month 5 리텐션 값만 Insert한다.
OR (cohort_yyyymm = DATE_TRUNC('MONTH', CURRENT_DATE) - INTERVAL '6' MONTH AND month_n = 5)
-- 현재 시점 기준으로 7개월 전의 코호트: Month 6 리텐션 값만 Insert한다.
OR (cohort_yyyymm = DATE_TRUNC('MONTH', CURRENT_DATE) - INTERVAL '7' MONTH AND month_n = 6)
"endif"
ORDER BY
1, 2
)
STEP 8) 출력한다.
SELECT
*
FROM
CTE_monthly_retention_inserted
;
6. 결론
Data Mart나 Batch Query에 대한 이론은 누구나 쉽게 온라인에서 공부할 수 있지만, 실제 Metrics 별로 모범이 될 만한 레퍼런스를 찾기가 어려운 것 같습니다. 특히, 리텐션의 경우 분명히 일회성 쿼리의 문제점을 해결해야 할 필요성이 클 것임에도 불구하고 저는 개인적으로 구글링을 통해서 적절한 레퍼런스를 전혀 찾지 못했습니다. 그래서 이참에 퍼블릭 레퍼런스를 제가 한 번 만들어보자는 결심이 들어 이렇게 글을 적어봤습니다.
그러나 저의 레퍼런스가 절대로 정답은 아닐 것입니다. Batch Query 모범 사례를 찾기 어렵다는 점은 그만큼 각 프로덕트의 도메인 특수성과 데이터의 형태가 극명하게 달라 절대불변의 정답이 없다는 의미일지도 모르겠습니다.
그러므로, 저의 사례는 가볍게 참고만 해주시고, 독자 분들께서 처한 다양한 특수성에 따라 가장 효율적인 리텐션 측정 환경을 구축하시길 바라겠습니다. 물론, 저의 논리적 오류나 개선 방향에 대한 피드백도 언제나 감사히 받겠습니다. 읽어주셔서 감사합니다.