
NOT IN 대신 JOIN을 통한 쿼리 최적화
2024-08-13
“이번 프로젝트에서는 엔터프라이즈 데이터 웨어하우스(EDW) 환경에서 발생한 쿼리 성능 문제를 해결하기 위해,
core_fct_events테이블의 Incremental 업데이트 전략을 최적화했습니다. 기존의 비효율적인NOT IN구문을LEFT JOIN으로 대체하여 데이터 중복 검사를 최적화함으로써, 오케스트레이션 전체 소요 시간을 50분에서 2분으로 단축했습니다. 이로 인해 약 96%의 성능 개선을 이루었으며, 데이터 처리 효율성과 시스템 자원 활용도를 크게 향상시켜 서비스의 안정성과 확장성을 강화했습니다.”
| Performance Summary |
|---|
- 오케스트레이션 소요 시간: 50분 → 2분 (96% ↓) |
목차
- STAR Summary
- Situation
- Tasks
- Actions
- Results
1. STAR Summary
Situation
- 엔터프라이즈 데이터 웨어하우스(EDW)에서 ELT 파이프라인의 오케스트레이션 작업이 예상보다 많은 시간을 소요하고 있었습니다. 특히,
core_fct_events테이블의 업데이트 과정에서 성능 문제가 발생하고 있었습니다.
Tasks
core_fct_events테이블의 Incremental Strategy를 개선하여 오케스트레이션 작업의 전체 소요 시간을 줄이는 것을 목표로 삼았습니다. 이를 통해 증가하는 데이터 트래픽을 원활하게 처리하고, 서비스의 신뢰성을 높이려 했습니다.
Actions
- 쿼리 성능을 저하시키던
NOT IN구문을LEFT JOIN으로 변경하여, 중복 데이터를 효과적으로 필터링하는 동시에 성능을 최적화했습니다.
Results
- 쿼리 최적화를 통해 오케스트레이션 전체 소요 시간이 50분에서 2분으로 대폭 감소했습니다. 이는 약 96%의 성능 개선을 의미하며, 데이터 처리 효율성을 크게 향상시켰습니다.
2. Situation
- 엔터프라이즈 데이터 웨어하우스(EDW)에서 ELT 파이프라인의 오케스트레이션 작업이 예상보다 많은 시간을 소요하고 있었습니다. 특히,
core_fct_events테이블의 업데이트 과정에서 성능 문제가 발생하고 있었습니다.
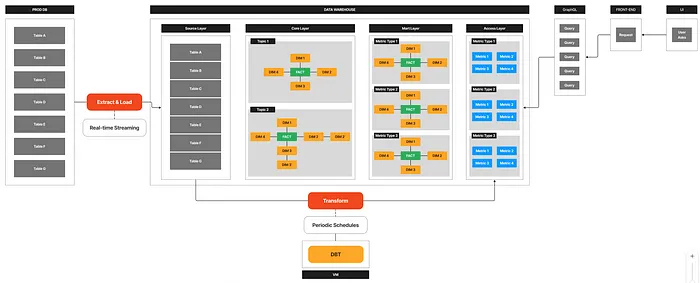
구체적인 상황
- 회사에서 B2B BI 서비스를 제공하기 위해 엔터프라이즈 데이터 웨어하우스(EDW) 환경을 운영하고 있었습니다. 매일 자정 무렵, 사용자 이벤트 데이터를 기반으로 한 복잡한 데이터 변환(Transformation) 작업이 수행되고 있었습니다. 그러나 이 과정에서 예상보다 시간이 오래 걸리는 문제가 발생했습니다. 특히,
core_fct_events라는 주요 이벤트 테이블의 Incremental 업데이트 과정이 전체 오케스트레이션 시간의 대부분을 차지하고 있었습니다. 이로 인해 데이터 갱신이 지연되고, 서비스 품질에 부정적인 영향을 줄 우려가 있었습니다.
3. Tasks
core_fct_events테이블의 Incremental Strategy를 개선하여 오케스트레이션 작업의 전체 소요 시간을 줄이는 것을 목표로 삼았습니다. 이를 통해 증가하는 데이터 트래픽을 원활하게 처리하고, 서비스의 신뢰성을 높이려 했습니다.
문제의 근본 원인
core_fct_events테이블의 업데이트 과정에서 발생하는 세 가지 주요 문제를 확인했습니다.
WITH
CTE_src_events AS (
SELECT
DISTINCT
datetime,
app_id,
user_id,
event_name
FROM
src_events
-- Incremental Strategy: Read rows with a datetime greater than the maximum datetime currently stored in the table.
{% if is_incremental() %}
WHERE
(SELECT MAX(datetime) FROM {{ this }}) < datetime
{% endif %}
)
SELECT
*
FROM
CTE_src_events
-- Incremental Strategy: Exclude data that already exists in the table. Do not insert those rows.
{% if is_incremental() %}
WHERE
(datetime, app_id, user_id, event_name) NOT IN (SELECT datetime, app_id, user_id, event_name FROM {{ this }})
{% endif %}
1. 데이터의 대용량성
core_fct_events테이블은 모든 사용자 이벤트 로그 데이터를 포함하고 있어 테이블 크기가 매우 컸습니다.
2. 중복 데이터의 존재
- 소스 테이블 자체에 중복 데이터가 존재하므로
DISTINCT키워드를 사용해 중복 제거를 해야 했습니다.
3. 비효율적인 중복 검사 방법
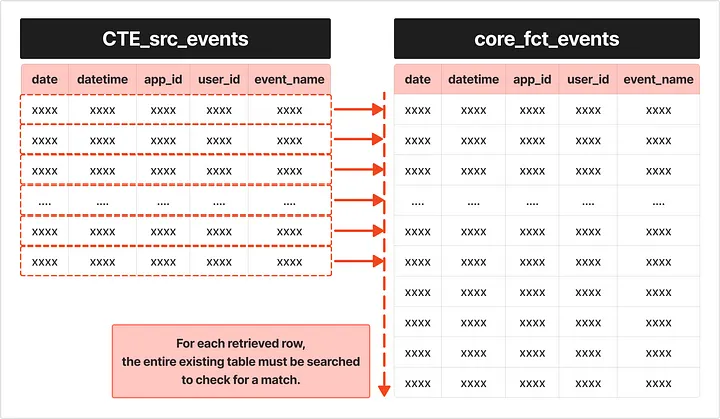
- 기존 쿼리에서
NOT IN구문을 사용하여 새로운 데이터와 기존 데이터를 비교하는 작업이 성능 병목의 주된 원인이었습니다. 이 구문은 Nested Loop 검색을 유발하여 테이블이 커질수록 성능이 저하될 수밖에 없었습니다.
4. Actions
- 쿼리 성능을 저하시키던
NOT IN구문을LEFT JOIN으로 변경하여, 중복 데이터를 효과적으로 필터링하는 동시에 성능을 최적화했습니다.
구체적인 조치 사항
1. 문제 분석 및 대안 탐색
- 먼저 기존의
NOT IN구문이 성능 병목을 일으키는 주요 원인임을 확인했습니다.NOT IN구문은 데이터베이스 엔진이 Nested Loop를 통해 모든 가능한 조합을 확인해야 하므로, 매우 비효율적입니다.
2. 쿼리 리팩토링
- 기존
NOT IN구문을LEFT JOIN으로 변경했습니다.LEFT JOIN을 사용하면 기존 테이블과 새 데이터 간의 비교를 보다 효율적으로 수행할 수 있습니다. 구체적으로,LEFT JOIN후NULL값을 필터링하여 기존 데이터에 없는 새로운 데이터만 삽입하도록 했습니다.
SELECT
MAIN.*
FROM
CTE_src_events MAIN
-- Incremental Strategy: Exclude data that already exists in the table. Do not insert those rows.
{% if is_incremental() %}
LEFT JOIN
{{ this }} THIS
ON MAIN.datetime = THIS.datetime
AND MAIN.app_id = THIS.app_id
AND MAIN.user_id = THIS.user_id
AND MAIN.event_name = THIS.event_name
WHERE
THIS.datetime IS NULL
{% endif %}
3. 성능 테스트 및 검증
- 쿼리 변경 후, 다양한 데이터 세트를 사용하여 성능 테스트를 진행했습니다. 이를 통해 쿼리 실행 시간이 크게 단축되었음을 확인하였습니다. 최적화된 쿼리 실행 시간은 기존의 50분에서 약 2분으로 줄어들었습니다.
5. Results
- 쿼리 최적화를 통해 오케스트레이션 전체 소요 시간이 50분에서 2분으로 대폭 감소했습니다. 이는 약 96%의 성능 개선을 의미하며, 데이터 처리 효율성을 크게 향상시켰습니다.
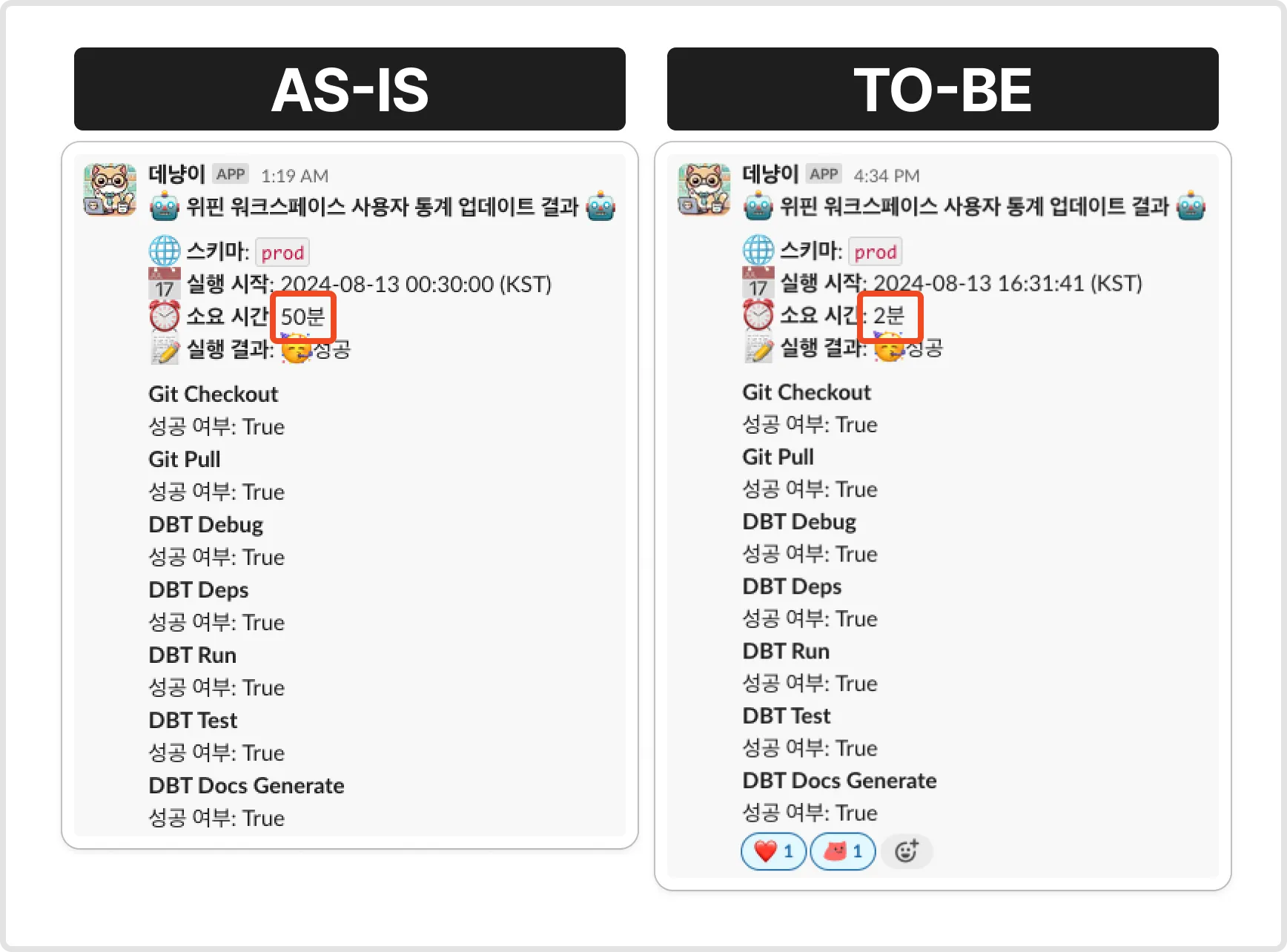
1. 성능 개선
- 오케스트레이션 전체 소요 시간이 50분에서 2분으로 대폭 감소했습니다. 이는 약 96%의 성능 개선으로, 데이터 처리 속도를 획기적으로 향상시켰습니다.
2. 리소스 효율성 향상
- 데이터베이스 자원의 효율적인 사용을 통해 시스템 부하가 감소하였으며, 이로 인해 다른 쿼리 및 작업도 더욱 원활하게 실행될 수 있었습니다.
3. 서비스 신뢰성 강화
- 데이터 갱신이 빠르고 안정적으로 이루어짐으로써 사용자에게 보다 신뢰성 있는 서비스를 제공할 수 있었습니다.
4. 미래 확장성 확보
- 트래픽 증가와 데이터 확장에 대비한 최적화 작업을 통해, 향후 데이터 처리 요구 사항을 보다 쉽게 충족할 수 있는 기반을 마련했습니다.
결론
- 이번 쿼리 최적화 프로젝트는 데이터 웨어하우스의 성능을 크게 향상시키는 동시에, 애널리틱스 엔지니어링 역량을 한층 강화하는 계기가 되었습니다. 데이터 처리 효율성을 극대화하고, BI 서비스의 품질을 높이는 데 중요한 기여를 했습니다.
Published by Joshua Kim
