
Query Optimization by Using JOIN Instead of NOT IN
2024-08-13
“In this project, I optimized the incremental update strategy for the
core_fct_eventstable to address query performance issues in our Enterprise Data Warehouse (EDW) environment. By replacing the inefficientNOT INclause with aLEFT JOIN, I streamlined the duplicate data check process, reducing the overall orchestration time from 50 minutes to 2 minutes. This resulted in approximately a 96% performance improvement, significantly enhancing data processing efficiency and system resource utilization, thereby strengthening service stability and scalability.”
| Performance Summary |
|---|
- Orchestration Time: 50 mins → 2 mins (96% ↓) |
Table of Contents
- STAR Summary
- Situation
- Tasks
- Actions
- Results
1. STAR Summary
Situation
- In our Enterprise Data Warehouse (EDW), the orchestration process of the ELT pipeline was taking significantly longer than expected. Specifically, there were performance issues during the update process of the
core_fct_eventstable.
Tasks
- The goal was to optimize the incremental strategy of the
core_fct_eventstable to reduce the overall orchestration time. This would enable us to handle increasing data traffic more efficiently and enhance service reliability.
Actions
- I replaced the
NOT INclause with aLEFT JOINto effectively filter duplicate data while optimizing performance.
Results
- Through query optimization, the total orchestration time was reduced from 50 minutes to 2 minutes, achieving approximately 96% performance improvement and significantly enhancing data processing efficiency.
2. Situation
- In our Enterprise Data Warehouse (EDW), the orchestration process of the ELT pipeline was taking significantly longer than expected. Specifically, there were performance issues during the update process of the
core_fct_eventstable.
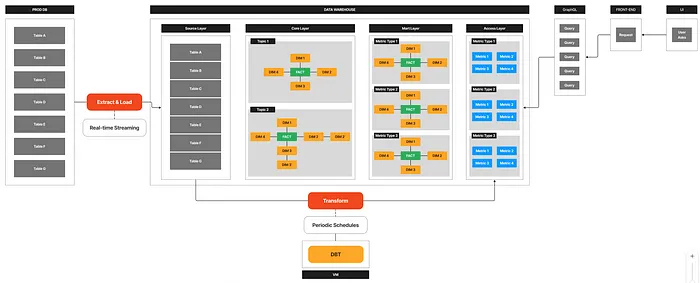
Specific Situation
- Our company operates an Enterprise Data Warehouse (EDW) environment to provide B2B BI services. Every midnight, a complex data transformation process based on user event data is performed. However, this process was taking longer than expected. In particular, the incremental update process of the
core_fct_eventstable, a key event table, was taking up most of the orchestration time. This delay in data refresh posed a risk of negatively impacting service quality.
3. Tasks
- The goal was to optimize the incremental strategy of the
core_fct_eventstable to reduce the overall orchestration time. This would enable us to handle increasing data traffic more efficiently and enhance service reliability.
Root Causes of the Problem
- I identified three major issues in the update process of the
core_fct_eventstable.
WITH
CTE_src_events AS (
SELECT
DISTINCT
datetime,
app_id,
user_id,
event_name
FROM
src_events
-- Incremental Strategy: Read rows with a datetime greater than the maximum datetime currently stored in the table.
{% if is_incremental() %}
WHERE
(SELECT MAX(datetime) FROM {{ this }}) < datetime
{% endif %}
)
SELECT
*
FROM
CTE_src_events
-- Incremental Strategy: Exclude data that already exists in the table. Do not insert those rows.
{% if is_incremental() %}
WHERE
(datetime, app_id, user_id, event_name) NOT IN (SELECT datetime, app_id, user_id, event_name FROM {{ this }})
{% endif %}
1. Large Data Volume
- The
core_fct_eventstable contained all user event log data, making the table size very large.
2. Presence of Duplicate Rows
- Due to the existence of duplicate data in the source table itself, the
DISTINCTkeyword had to be used to remove duplicates.
3. Inefficient Duplicate Check Method
- The existing query used the
NOT INclause to compare new data with existing data, which was the main cause of the performance bottleneck. This clause triggers nested loop searches, causing performance degradation as the table size increases.
4. Actions
- I replaced the
NOT INclause with aLEFT JOINto effectively filter duplicate data while optimizing performance.
Specific Actions Taken
1. Problem Analysis and Alternative Exploration
- First, I identified that the
NOT INclause was the primary cause of the performance bottleneck. TheNOT INclause requires the database engine to check all possible combinations through nested loops, making it highly inefficient.
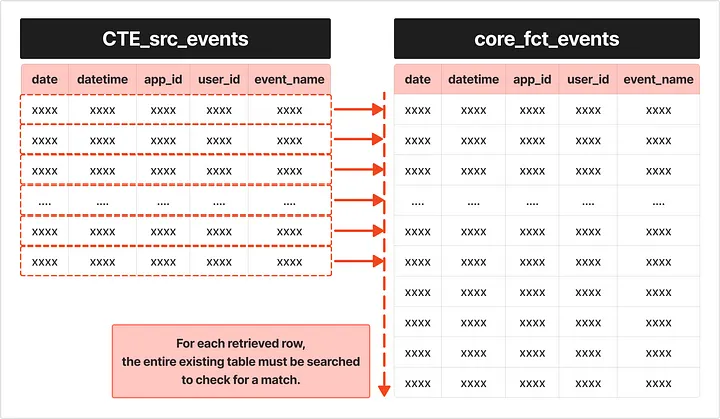
2. Query Refactoring
- I replaced the existing
NOT INclause with aLEFT JOIN. Using aLEFT JOINallows for more efficient comparison between the existing table and the new data. Specifically, after performing theLEFT JOIN, only new data that does not exist in the existing data is inserted by filtering forNULLvalues.
SELECT
MAIN.*
FROM
CTE_src_events MAIN
-- Incremental Strategy: Exclude data that already exists in the table. Do not insert those rows.
{% if is_incremental() %}
LEFT JOIN
{{ this }} THIS
ON MAIN.datetime = THIS.datetime
AND MAIN.app_id = THIS.app_id
AND MAIN.user_id = THIS.user_id
AND MAIN.event_name = THIS.event_name
WHERE
THIS.datetime IS NULL
{% endif %}
3. Performance Testing and Validation
- After modifying the query, I conducted performance tests using various data sets. This confirmed that the query execution time was significantly reduced. The optimized query execution time was reduced from 50 minutes to approximately 2 minutes.
5. Results
- Through query optimization, the total orchestration time was reduced from 50 minutes to 2 minutes, achieving approximately 96% performance improvement and significantly enhancing data processing efficiency.
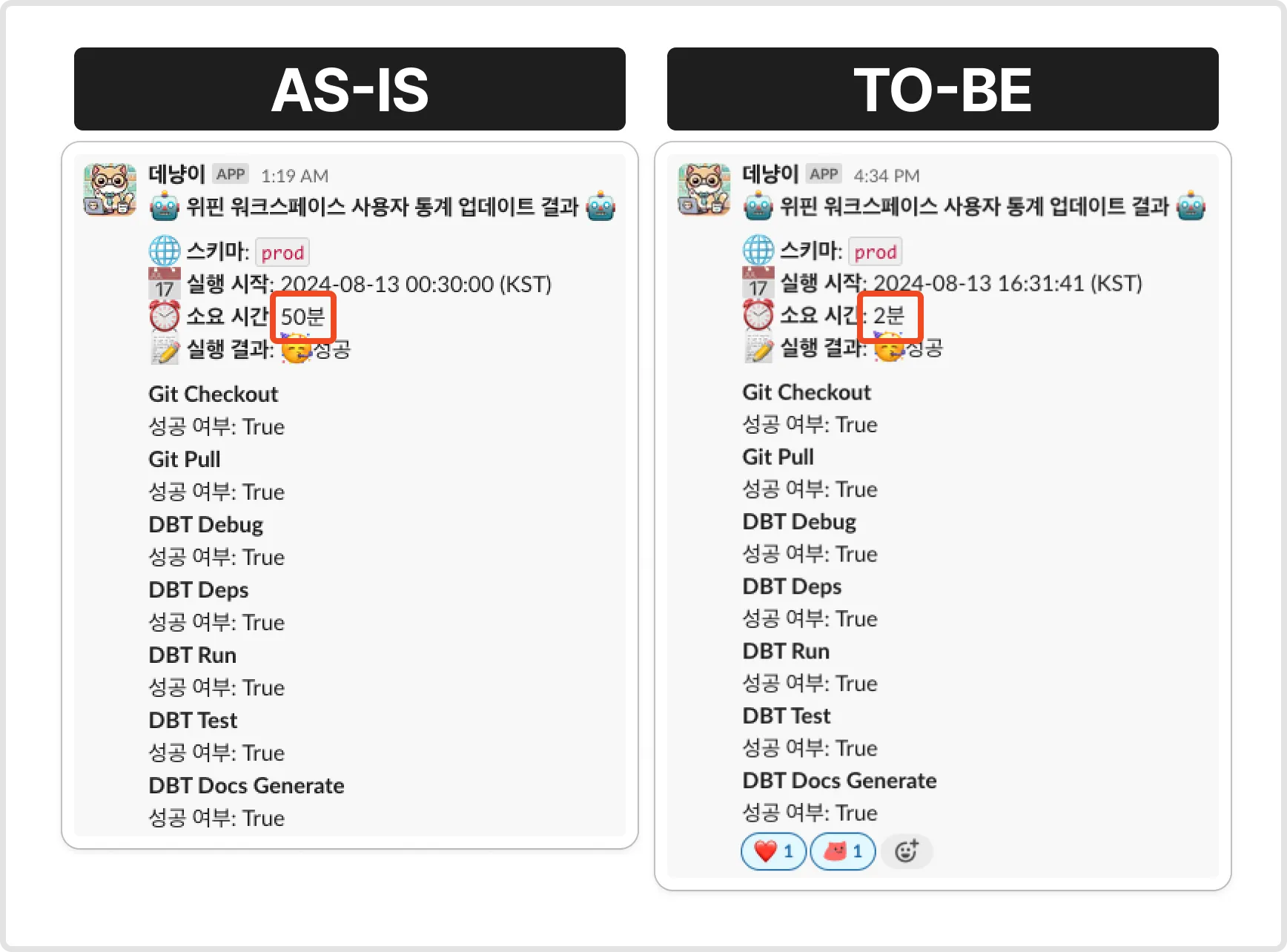
1. Performance Improvement
- The total orchestration time was reduced from 50 minutes to 2 minutes, representing approximately 96% performance improvement, drastically enhancing data processing speed.
2. Improved Resource Efficiency
- Efficient use of database resources reduced system load, allowing other queries and tasks to execute more smoothly.
3. Enhanced Service Reliability
- Faster and more reliable data updates provided a more dependable service to users.
4. Future Scalability Secured
- The optimization efforts in preparation for increased traffic and data expansion have laid a foundation for easily meeting future data processing requirements.
Conclusion
- This query optimization project significantly enhanced the performance of our data warehouse while also strengthening our analytics engineering capabilities. It was a valuable contribution to maximizing data processing efficiency and improving the quality of our BI services.
Published by Joshua Kim
