IP 주소-국가 매핑 쿼리 최적화
“데이터 웨어하우스에서 IP 주소를 사용해 사용자의 국가 정보를 매핑하는 작업을 최적화하였습니다. 기존 방식은 연산 시간이 길어 비효율적이었으나, 새로운 접근 방식을 통해 쿼리 실행 시간을 90% 감소시켰습니다.”
| Performance Summary |
|---|
- 쿼리 실행 시간: 100분 → 10분 |
목차
- STAR Summary
- Situation
- Tasks
- Actions
- Results
1. STAR Summary
Situation
- 글로벌 서비스를 운영하는 환경에서 사용자의 접속 IP 주소를 기반으로 국가 정보를 매핑해야 했습니다. PostgreSQL을 사용하여 이 작업을 수행했으나, 기존 접근 방식으로 인해 성능 저하 문제가 발생했습니다. 기존 쿼리로는 너무 많은 시간이 소요되었으며, 이는 데이터 웨어하우스 운영에 큰 부담을 주고 있었습니다.
Tasks
- 기존의 IP 주소 매핑 쿼리를 최적화하여 처리 시간을 대폭 줄이는 것이 목표였습니다. 이 작업을 통해 Transformation 과정의 효율성을 높여, 더 나은 데이터 웨어하우스 성능을 달성해야 했습니다. 구체적으로는 IP 주소 매핑 시 연산 과정을 최적화하고, JOIN 조건의 효율성을 높이는 것이 핵심 과제였습니다.
Actions
- 기존 접근 방식 분석
- 기존 쿼리에서
<<=연산자를 사용하여 CIDR 네트워크에 IP 주소를 매핑하는 방법을 사용했습니다. 이는 성능 저하의 주요 원인으로 파악되었습니다.
- 기존 쿼리에서
- 새로운 테이블 생성
- 기존 테이블을 가공하여
dim_ips_countries테이블을 생성했습니다.- 이 테이블은
start_ip와end_ip칼럼을 가지고 있습니다. - 비교 연산의 효율성을 위해 IP 주소를 BIGINT 타입으로 변환했습니다.
- 이 테이블은
- 기존 테이블을 가공하여
- Index 생성
start_ip와end_ip칼럼을 Index로 생성하여 검색 성능을 극대화했습니다.
- 쿼리 최적화
- 기존의
<<=연산자를BETWEEN연산자로 대체하여, IP 주소 비교 작업을 단순화하고 경량화된 연산을 수행하도록 쿼리를 재구성했습니다.
- 기존의
Results
- 최적화된 쿼리를 통해 실행 시간이 90% 대폭 감소하여 데이터 웨어하우스 성능 향상을 가져왔습니다.
2. Situation
- 글로벌 서비스를 운영하는 환경에서 사용자의 접속 IP 주소를 기반으로 국가 정보를 매핑해야 했습니다. PostgreSQL을 사용하여 이 작업을 수행했으나, 기존 접근 방식으로 인해 성능 저하 문제가 발생했습니다. 기존 쿼리로는 너무 많은 시간이 소요되었으며, 이는 데이터 웨어하우스 운영에 큰 부담을 주고 있었습니다.
문제 요약
- 글로벌 서비스를 운영하는 환경에서 사용자들이 접속할 때마다 수집되는 IP 주소를 지리 정보인 국가로 매핑하는 작업이 필요했습니다. 이를 위해 PostgreSQL의 CIDR 연산자를 사용하여 IP 주소를 국가명과 매핑하는 테이블을 구성했지만, 기존 방식은 매우 비효율적이었습니다.
구체적인 문제 상황
src_sessions테이블의session_ip칼럼을src_cidrs_countries테이블의cidr칼럼에 매핑하여fct_sessions테이블을 생성하는 작업이 핵심 문제였습니다.- 기존 쿼리는
<<=연산자를 사용하여 IP 주소가 특정 CIDR 네트워크에 포함되는지를 확인하는 방식으로 이루어졌습니다. 그러나 이 방법은 대규모 데이터 처리 시 성능 문제가 발생하여, 쿼리 실행 시간이 지나치게 많이 소요되었습니다. 이는 데이터 웨어하우스의 성능을 저하시키고, 운영에 심각한 지장을 초래했습니다.
3. Tasks
- 기존의 IP 주소 매핑 쿼리를 최적화하여 처리 시간을 대폭 줄이는 것이 목표였습니다. 이 작업을 통해 Transformation 과정의 효율성을 높여, 더 나은 데이터 웨어하우스 성능을 달성해야 했습니다. 구체적으로는 IP 주소 매핑 시 연산 과정을 최적화하고, JOIN 조건의 효율성을 높이는 것이 핵심 과제였습니다.
주어진 과제
- 기존의 비효율적인 쿼리 실행 시간을 대폭 줄이는 것이었습니다.
1. 데이터 처리 속도 향상
- 실행 시간을 줄여 데이터 처리 효율성을 높이고, 서비스 운영에 방해가 되지 않도록 하는 것
2. 쿼리 최적화
- IP 주소와 국가 정보의 매핑 작업을 보다 효율적으로 수행할 수 있는 최적화된 쿼리 구조를 설계하고 구현하는 것
3. 시스템 성능 개선
- 데이터 웨어하우스의 전반적인 성능을 개선하여 미래의 데이터 확장 및 증가에도 대응할 수 있는 기반을 마련하는 것
4. Actions
- 기존 접근 방식 분석
- 기존 쿼리에서
<<=연산자를 사용하여 CIDR 네트워크에 IP 주소를 매핑하는 방법을 사용했습니다. 이는 성능 저하의 주요 원인으로 파악되었습니다.- 새로운 테이블 생성
- 기존 테이블을 가공하여
dim_ips_countries테이블을 생성했습니다.
- 이 테이블은
start_ip와end_ip칼럼을 가지고 있습니다.- 비교 연산의 효율성을 위해 IP 주소를 BIGINT 타입으로 변환했습니다.
- Index 생성
start_ip와end_ip칼럼을 Index로 생성하여 검색 성능을 극대화했습니다.- 쿼리 최적화
- 기존의
<<=연산자를BETWEEN연산자로 대체하여, IP 주소 비교 작업을 단순화하고 경량화된 연산을 수행하도록 쿼리를 재구성했습니다.
1. 기존 접근 방식 분석
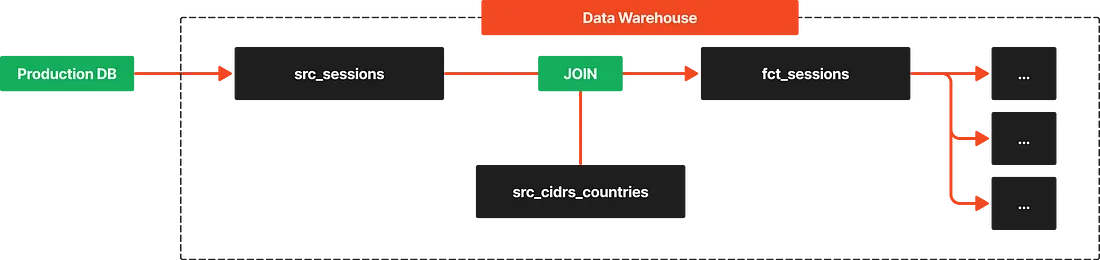
(STEP 1) src_cidrs_countries 테이블에 Index를 생성합니다.
src_sessions테이블과 JOIN시cidr칼럼을 빈번하게 스캔해야 하므로, 이를 Index로 생성했습니다.View code
CREATE INDEX idx_cidr ON src_cidrs_countries (cidr);
(STEP 2) src_cidrs_countries 테이블과 src_sessions 테이블을 JOIN한 fct_sessions 테이블을 생성했습니다.
- JOIN 과정에서
<<=연산자를 사용했습니다. - 그러나 이 연산자는 CIDR 타입 간의 비교를 수행하는 데 연산 비용이 높아, 대규모 데이터 처리 시 성능 저하의 원인이 되었습니다.
View code
CREATE TABLE fct_sessions AS SELECT S.session_id, S.user_id, C.country FROM src_sessions S LEFT JOIN src_cidrs_countries C ON S.session_ip::INET <<= C.cidr;
2. 새로운 테이블 생성
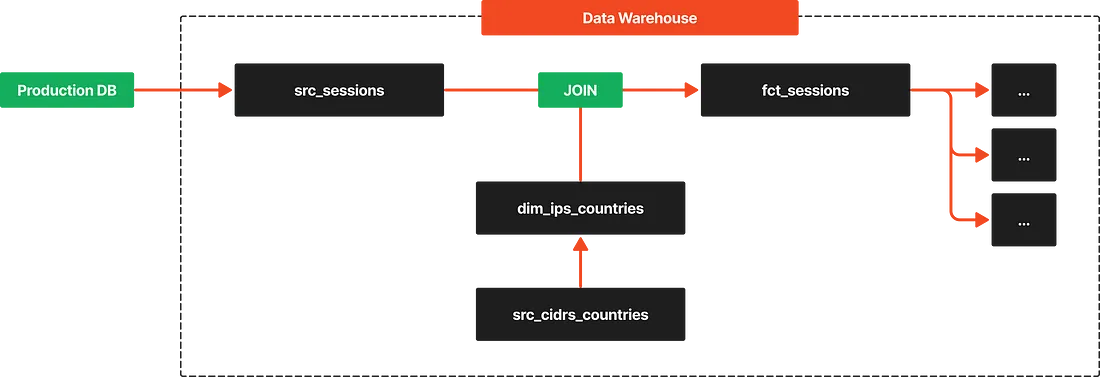
- 기존의
src_cidrs_countries테이블을 가공하여dim_ips_countries테이블을 새롭게 설계했습니다. 이 테이블에 CIDR 연산을 최소화하기 위해 각 CIDR 값에 대해 IP 주소 범위를 나타내는start_ip와end_ip칼럼을 추가했습니다. - IP 주소를 BIGINT 타입으로 변환하여 저장함으로써, 연산 속도를 크게 향상시켰습니다.
start_ip와end_ip는 CIDR 범위 내에서 가장 낮은 IP와 가장 높은 IP를 나타내며, 이를 통해 CIDR 네트워크 내 IP 주소 확인 작업을 단순화했습니다.
View code
CREATE TABLE dim_ips_countries AS
SELECT
cidr,
('x' ||
LPAD(TO_HEX((SPLIT_PART(HOST(cidr), '.', 1)::INTEGER)), 2, '0') ||
LPAD(TO_HEX((SPLIT_PART(HOST(cidr), '.', 2)::INTEGER)), 2, '0') ||
LPAD(TO_HEX((SPLIT_PART(HOST(cidr), '.', 3)::INTEGER)), 2, '0') ||
LPAD(TO_HEX((SPLIT_PART(HOST(cidr), '.', 4)::INTEGER)), 2, '0')
)::BIT(32)::BIGINT AS start_ip,
('x' ||
LPAD(TO_HEX((SPLIT_PART(HOST(BROADCAST(cidr)), '.', 1)::INTEGER)), 2, '0') ||
LPAD(TO_HEX((SPLIT_PART(HOST(BROADCAST(cidr)), '.', 2)::INTEGER)), 2, '0') ||
LPAD(TO_HEX((SPLIT_PART(HOST(BROADCAST(cidr)), '.', 3)::INTEGER)), 2, '0') ||
LPAD(TO_HEX((SPLIT_PART(HOST(BROADCAST(cidr)), '.', 4)::INTEGER)), 2, '0')
)::BIT(32)::BIGINT AS end_ip,
country
FROM
src_cidrs_countries;
3. Index 생성
src_sessions테이블과 JOIN시start_ip및end_ip칼럼을 빈번하게 스캔해야 하므로, 이 2개 칼럼을 Index로 생성했습니다.- 이 Index는 IP 주소 범위 내에서 효율적으로 값을 찾을 수 있도록 설계되었으며, JOIN 연산 시 빠른 검색이 가능하게 되었습니다.
View code
CREATE INDEX idx_ip_range ON dim_ips_countries (start_ip, end_ip);
4. 쿼리 최적화
- 기존의
<<=연산자를BETWEEN연산자로 대체하여, IP 주소 비교 작업을 단순화하고 경량화된 연산을 수행하도록 쿼리를 재구성했습니다. src_sessions테이블의session_ip칼럼도 CIDR에서 IP 주소를 추출한 후 BIGINT 타입으로 변환하여dim_ips_countries테이블의start_ip와end_ip칼럼과 비교했습니다.View code
CREATE TABLE fct_sessions AS SELECT S.session_id, S.user_id, C.country FROM ( SELECT session_id, user_id, ('x' || LPAD(TO_HEX((SPLIT_PART(HOST(session_ip::INET), '.', 1)::INTEGER)), 2, '0') || LPAD(TO_HEX((SPLIT_PART(HOST(session_ip::INET), '.', 2)::INTEGER)), 2, '0') || LPAD(TO_HEX((SPLIT_PART(HOST(session_ip::INET), '.', 3)::INTEGER)), 2, '0') || LPAD(TO_HEX((SPLIT_PART(HOST(session_ip::INET), '.', 4)::INTEGER)), 2, '0') )::BIT(32)::BIGINT AS session_ip FROM src_sessions ) S LEFT JOIN src_cidrs_countries C ON S.session_ip BETWEEN C.start_ip AND C.end_ip;
5. Results
- 최적화된 쿼리를 통해 실행 시간이 90% 대폭 감소하여 데이터 웨어하우스 성능 향상을 가져왔습니다.
1. 긍정적인 결과
- 최적화된 접근 방식을 통해 쿼리 실행 시간이 기존 100x시간에서 약 10x시간으로 감소하였습니다. 이는 실행 시간의 약 90%를 줄인 결과로, 데이터 처리 속도와 시스템 성능이 크게 개선되었습니다. 특히, 신규 접근 방식은 대규모 데이터 처리 시에도 안정적인 성능을 유지할 수 있도록 하였으며, 향후 데이터 증가에도 유연하게 대응할 수 있는 기반을 마련했습니다.
- 이 최적화 작업은 데이터 웨어하우스의 효율성을 극대화하여 운영 비용을 절감하고, 더 나은 데이터 분석과 서비스 제공이 가능하도록 했습니다. 결과적으로, 시스템의 전반적인 성능이 크게 향상되었으며, 이로 인해 회사의 데이터 운영 전략에 중요한 기여를 할 수 있었습니다.
2. 교훈
- 아래 그림과 같이, SQL의 JOIN은 Nested Loop 탐색 과정이 일어나므로 가장 면밀하게 검토해야 할 부분이었습니다.
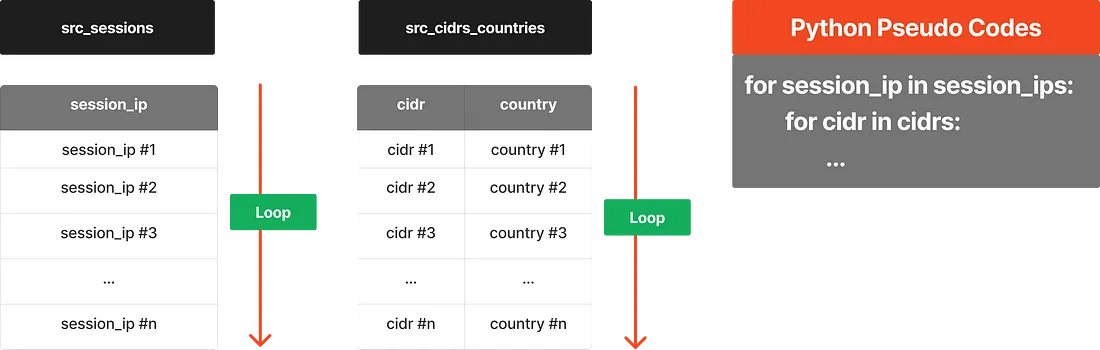
(TIP 1) JOIN의 조건 역할을 하는 칼럼은 최대한 가벼운 타입을 지녀야 한다.
- 기존 접근 방식에서는
cidr칼럼이 CIDR 타입이었으나, 신규 접근 방식에서는 이를 BIGINT로 Parse하여 타입을 경량화시켰습니다.
(TIP 2) JOIN의 조건 역할을 하는 연산자는 최대한 가벼운 과정이 되어야 한다.
- 기존 접근 방식에서는
>>=라는 다소 무거운 연산자를 사용했으나, 신규 접근 방식에서는 이를BETWEEN연산자를 사용하여 부담을 줄였습니다.