GA4 기반 데이터 웨어하우스 구축 후기
“이 글은 Google Analytics 4(GA4) 데이터를 효율적으로 활용하기 위해 데이터 웨어하우스를 구축한 과정과 결과를 공유하는 후기입니다. 기존에는 GA4 Export Table에 직접 쿼리를 실행하는 방식이었지만, 스키마 복잡성, 느린 쿼리 실행 시간, 높은 비용 문제를 해결하기 위해 데이터 마트를 구성하고, dbt를 활용한 Incremental Strategy를 적용하여 성능을 최적화했습니다. 그 결과, 쿼리 속도가 획기적으로 향상되고 비용이 절감되었으며, 조직 내 데이터 접근성이 높아져 보다 효율적인 데이터 활용이 가능해졌습니다.”
목차
- 들어가는 글
- 문제 상황 진단
- 2.1. 소스 테이블의 까다로운 스키마
- 2.2. 느린 쿼리 실행 시간과 높은 쿼리 비용
- 해결 방법: 데이터 웨어하우스 구축
- 3.1. 각 데이터 마트 테이블의 간결한 스키마
- 3.2. 빠른 쿼리 실행 시간과 낮은 쿼리 비용
- 데이터 웨어하우스 구축 방법
- 4.1. 데이터 웨어하우스 Data Lineage 미리보기
- 4.2.
core_fct_events테이블 모델 만들기 - 4.3. 각 event-specific 테이블 모델 만들기
- 4.4.
core_dim_users테이블 모델 만들기 - 4.5. Incremental Strategy 전략을 위한 Where Statement와 Variables 관리
- 결과
- 5.1. 쿼리 속도 향상 및 비용 감소
- 5.2. 조직의 데이터 접근성 향상
- 나가는 글
1. 들어가는 글
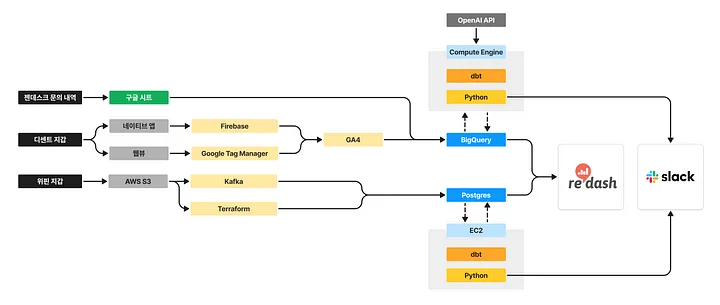
아이오트러스트 데이터 파이프라인 간략화
저희 회사는 B2C 프로덕트 디센트 지갑과 B2B2C 프로덕트 위핀 지갑을 운영하고 있습니다. 이 중, 디센트 지갑의 경우 기본적으로 모두 Google Analytics 4를 거쳐 BigQuery에 데이터를 적재하고 있는데요!
많은 스타트업들이 BigQuery에 적재된 Google Analytics 4 Export Table에 직접 쿼리를 실행하는 방식으로 데이터를 활용하고 계실 것입니다. 그러나 이러한 “소스 테이블에 의존된” 쿼리 실행 방식은 시간이 흐를수록 쿼리 비용과 시간에 큰 장애를 낳기 쉽습니다.
따라서 저는 이를 극복하기 위해 “정말 흔치 않은” GA4 기반 데이터 웨어하우스 구조를 도입했고, 이번 글에서는 이에 대한 후기를 전달해드리고자 합니다.
2. 문제 상황 진단
2.1. 소스 테이블의 까다로운 스키마
BigQuery에 스트리밍되는 Google Analytics 4 Export Table은 구조적 확장에 따른 유연성을 갖추고자 각 이벤트 파라미터나 구매 제품 정보가 RECORD 타입으로 이루어져 있습니다. Columnar Database 구조를 통해 스토리지 비용을 줄이기 위한 구글의 채택 방식인 것이죠.
가령, event_params 의 경우 마치 JSON 형식 처럼 Key, Value가 분리된 형태로 적재되어 있어서 이를 다뤄보지 않은 사람에게는 쿼리 작성 난이도가 꽤 높은 편입니다.
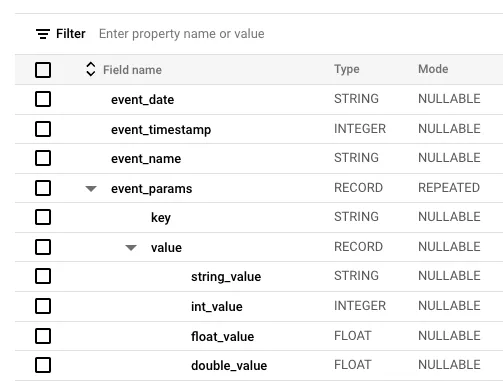
GA4 소스 테이블 스키마 (공개 샘플 테이블)
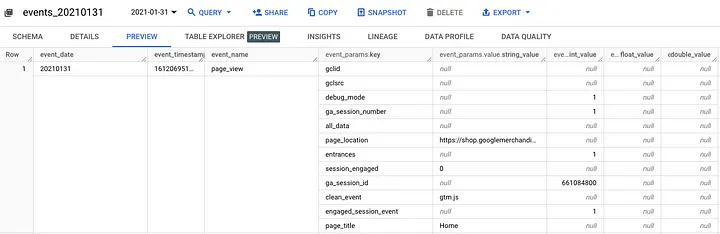
GA4 소스 테이블 미리보기 (공개 샘플 테이블)
따라서 단순히 특정 페이지의 방문 수만 추출하려고 하더라도, 아래와 같이 복잡한 쿼리 작성이 필요합니다. 처음 접하는 사람에게는 분명 학습의 어려움이 느껴질 것입니다.
SELECT
event_date,
COUNT(DISTINCT ga_session_id) AS sessions_cnt,
COUNT(DISTINCT user_pseudo_id) AS users_cnt
FROM
`events_*`
WHERE
_table_suffix BETWEEN '20240101' AND '20241231'
AND event_name = 'page_view'
AND (SELECT value.string_value FROM UNNEST (event_params) WHERE key = 'page_location') LIKE '%store.dcentwallet.com/pages/dcent-biometric-crypto-wallet%'
GROUP BY
1
ORDER BY
1
;
따라서 누구나 간결화된 테이블 스키마를 통해 쉽게 쿼리를 작성할 수 있는 환경이 요구되는 것입니다.
2.2. 느린 쿼리 실행 시간과 높은 쿼리 비용
소스 테이블을 향해 직접 쿼리를 실행하면 시간이 흐를수록 쿼리 실행 시간이 느릴 뿐만 아니라, 쿼리 비용 부담도 가파르게 증가하게 됩니다.
특히, 쿼리를 작성하지는 않지만 대시보드를 소비하는 동료의 입장에서, 대시보드 업데이트 과정이 오래 걸리면 데이터 활용도에 큰 영향을 미치게 됩니다. 조금 극단적이기는 하지만 아래와 같은 명언도 있죠.
“대시보드 업데이트 시간이 5초를 넘어가는 순간, 마케터와 디자이너는 바로 이탈해버리기 마련이다. 따라서 쿼리 최적화는 데이터 활용도에 매우 중요한 영향을 끼친다.”
3. 해결 방법: 데이터 웨어하우스 구축
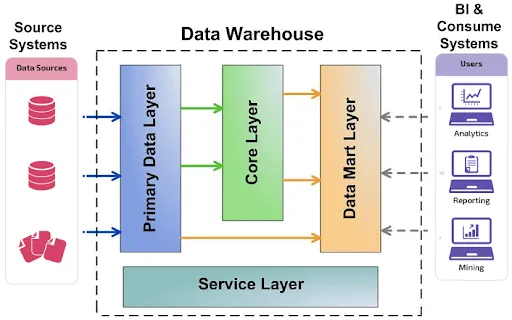
데이터 웨어하우스를 구축하면 위에서 언급해드린 문제를 드라마틱하게 극복할 수 있습니다.
3.1. 각 데이터 마트 테이블의 간결한 스키마
동료들이 쉽게 쿼리를 실행할 수 있도록, 각 데이터 마트와 테이블 구조를 간결화할 수 있습니다. 이를 통해 데이터 분석가나 애널리틱스 엔지니어에 대한 의존도를 줄이고, 즉각적으로 업무에 활용할 수 있는 데이터 조회 환경을 구축할 수 있게 됩니다.
3.2. 빠른 쿼리 실행 시간과 낮은 쿼리 비용
데이터 마트의 테이블들은 목적에 맞는 Columns와 반드시 필요한 Rows로만 구성되어 있기 때문에 소스 테이블에 비해 사이즈가 훨씬 경감되기 마련입니다. 이 덕분에 데이터 마트를 향해 쿼리를 실행함으로써 쿼리 실행 시간과 쿼리 비용이 급격하게 줄어들 수 있습니다.
4. 데이터 웨어하우스 구축 방법
4.1. 데이터 웨어하우스 Data Lineage 미리보기
디센트 앱 데이터 웨어하우스 Core Layer의 Data Lineage는 다음과 같이 구성되어 있습니다. 즉, 소스 테이블에 해당하는 ga4.events 및 ga4.events_intraday로부터 각 테이블들이 Star Schema 형태로 생성됩니다.
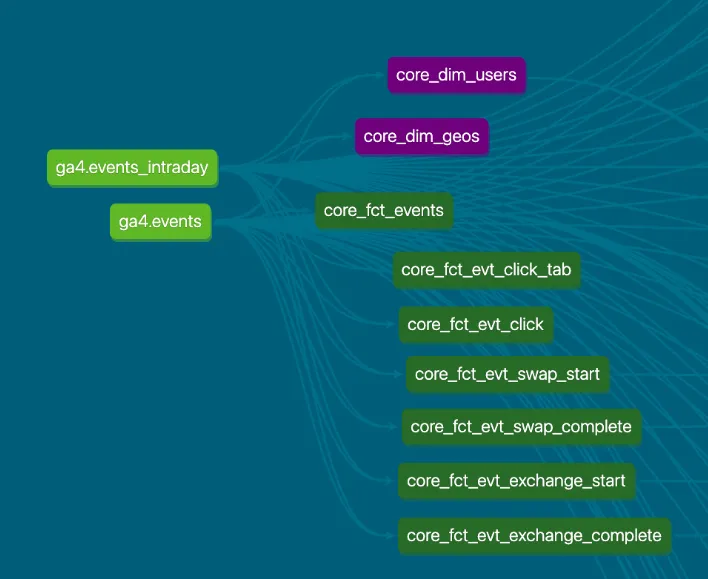
디센트 앱 데이터 웨어하우스 Data Lineage의 일부
4.2.core_fct_events 테이블 모델 만들기
우선, 모든 이벤트들이 적재된 기본 Fact 테이블을 만들었습니다. 각 이벤트들이 지닌 이벤트 파라미터는 제각기 다르므로 이는 제외한 상태에서 최대한 많은 정보를 담아냈어요.
SELECT
DISTINCT
PARSE_DATE('%Y%m%d', event_date) AS date,
DATETIME(TIMESTAMP_MICROS(event_timestamp), 'Asia/Seoul') AS datetime,
COALESCE(user_pseudo_id, 'UNK') AS user_pseudo_id,
COALESCE((SELECT value.int_value FROM UNNEST (event_params) WHERE key = 'ga_session_id'), -1) AS ga_session_id,
COALESCE((SELECT value.int_value FROM UNNEST (event_params) WHERE key = 'ga_session_number'), -1) AS ga_session_number,
event_name,
COALESCE(device.web_info.hostname, 'UNK') AS hostname,
COALESCE((SELECT value.string_value FROM UNNEST (event_params) WHERE key = 'page_location'), 'UNK') AS page_location_full,
COALESCE((SELECT FROM UNNEST (event_params) WHERE key = 'page_location'), 'UNK') AS page_location,
COALESCE((SELECT value.string_value FROM UNNEST (event_params) WHERE key = 'page_title'), 'UNK') AS page_title,
COALESCE(
LOWER((SELECT value.string_value FROM UNNEST (user_properties) WHERE key = 'xxx')),
LOWER(CAST((SELECT value.double_value FROM UNNEST (user_properties) WHERE key = 'xxx') AS STRING)),
LOWER(CAST((SELECT value.float_value FROM UNNEST (user_properties) WHERE key = 'xxx') AS STRING)),
LOWER(CAST((SELECT value.int_value FROM UNNEST (user_properties) WHERE key = 'xxx') AS STRING)),
'UNK'
) AS xxx,
COALESCE(platform, 'UNK') AS platform,
COALESCE(device.operating_system, 'UNK') AS device_os,
COALESCE(device.category, 'UNK') AS device_category,
COALESCE(app_info.version, 'UNK') AS app_version,
CASE
WHEN geo.continent IS NULL THEN 'UNK'
WHEN geo.continent = '' THEN 'UNK'
WHEN geo.continent = '(not set)' THEN 'UNK'
ELSE geo.continent
END AS continent,
CASE
WHEN geo.country IS NULL THEN 'UNK'
WHEN geo.country = '' THEN 'UNK'
WHEN geo.country = '(not set)' THEN 'UNK'
ELSE geo.country
END AS country,
COALESCE(traffic_source.name, 'UNK') AS first_utm_campaign,
COALESCE(traffic_source.medium, 'UNK') AS first_utm_medium,
COALESCE(traffic_source.source, 'UNK') AS first_utm_source,
COALESCE((SELECT value.string_value FROM UNNEST (event_params) WHERE key = 'campaign_id'), 'UNK') AS event_utm_campaign_id,
COALESCE((SELECT value.string_value FROM UNNEST (event_params) WHERE key = 'campaign'), 'UNK') AS event_utm_campaign,
COALESCE((SELECT value.string_value FROM UNNEST (event_params) WHERE key = 'medium'), 'UNK') AS event_utm_medium,
COALESCE((SELECT value.string_value FROM UNNEST (event_params) WHERE key = 'source'), 'UNK') AS event_utm_source,
COALESCE((SELECT value.string_value FROM UNNEST (event_params) WHERE key = 'term'), 'UNK') AS event_utm_term,
COALESCE((SELECT value.string_value FROM UNNEST (event_params) WHERE key = 'content'), 'UNK') AS event_utm_content,
...
FROM
WHERE
event_date IS NOT NULL
AND event_timestamp IS NOT NULL
AND event_name IS NOT NULL
...
(1) GA4 Export Table에는 모종의 이유로 완전히 동일한 이벤트가 연달아 2번 수집되는 경우가 많습니다. 특히, 앱의 개발 소스 코드의 구조에 따라 이런 경우가 빈번하게 발생하는데요. 이는 Aggregation 과정시 데이터 왜곡이 발생하기 쉬으므로 연산 비용이 발생하더라도 DISTINCT 를 통해 중복을 반드시 제거하도록 했습니다.
(2) 각 이벤트 파라미터나 사용자 속성의 경우 UNNEST를 통해 Select Subquery를 사용함으로써 모델 쿼리문을 간결화하도록 노력했습니다.
(3) Null Handling을 위해 다음과 같은 규칙을 정했습니다. 이는 Aggregation 과정에서 Null의 존재로 인한 데이터 왜곡 현상을 원천적으로 차단하기 위한 조치였어요.
- String: “UNK” (unknown)
- Number: -1
- Date: “1900–01–01”
(4) event_date, event_timestamp, event_name 값이 존재하지 않는 Rows의 경우 애초에 모델에 적재하지 않도록 했습니다. 세 가지 값 중 하나라도 알 수 없다면 데이터로서 아무런 가치를 창출할 수 없다고 판단했기 때문이에요.
(5) page_location의 경우, 페이지 URL 내의 쿼리 요소가 제각기 다를 경우 이를 전처리하는 과정이 쿼리 작성자에게 시간 소모가 많습니다. 따라서 clean_url이라는 dbt 매크로 함수를 직접 정의하여 깨끗하고 규칙적으로 출력될 수 있도록 적용했어요.
clean_url매크로 사례
{% macro clean_url(column_name) %}
REPLACE(
REGEXP_REPLACE(
REGEXP_REPLACE(
LOWER({{ column_name }}),
r'(\?.*)$',
''
),
r'/$',
''
),
'https://',
''
)
{% endmacro %}
4.3. 각 event-specific 테이블 모델 만들기
전술해드렸듯이, 각 이벤트마다 완전히 다른 이벤트 파라미터 구조를 지니고 있습니다. 이벤트 파라미터 정보는 각 이벤트 별로 독립적으로 적용되도록 구축하는 것이 필요했는데요. 가령, 조직의 이벤트 택소노미가 변경되어 신규 파라미터를 수집하게 되었다면, 이를 데이터 웨어하우스 전체에 적용하게 되면 쿼리 비용이 급격하게 증가할 수밖에 없을 것입니다. 따라서 이를 event-specific하게 관리함으로써, 반드시 필요한 이벤트 전용 테이블에만 영향을 끼치도록 했습니다. 소스 테이블의 변동으로 인한 영향을 최소화하기 위한 설계인 것이죠.
가령, 아래 모델 쿼리문은 click_tab이라는 이벤트와 to_tab_name 파라미터 정보만을 담은 core_fct_evt_click_tab입니다.
SELECT
DISTINCT
PARSE_DATE('%Y%m%d', event_date) AS date,
DATETIME(TIMESTAMP_MICROS(event_timestamp), 'Asia/Seoul') AS datetime,
COALESCE(user_pseudo_id, 'UNK') AS user_pseudo_id,
COALESCE((SELECT value.int_value FROM UNNEST (event_params) WHERE key = 'ga_session_id'), -1) AS ga_session_id,
COALESCE((SELECT value.int_value FROM UNNEST (event_params) WHERE key = 'ga_session_number'), -1) AS ga_session_number,
COALESCE(device.web_info.hostname, 'UNK') AS hostname,
COALESCE((SELECT value.string_value FROM UNNEST (event_params) WHERE key = 'page_location'), 'UNK') AS page_location_full,
COALESCE((SELECT {{ clean_url('value.string_value') }} FROM UNNEST (event_params) WHERE key = 'page_location'), 'UNK') AS page_location,
COALESCE((SELECT value.string_value FROM UNNEST (event_params) WHERE key = 'page_title'), 'UNK') AS page_title,
COALESCE((SELECT {{ clean_url('value.string_value') }} FROM UNNEST (event_params) WHERE key = 'to_tab_name'), 'UNK') AS to_tab_name,
...
FROM
{{ source('ga4', 'events') }}
WHERE
event_date IS NOT NULL
AND event_timestamp IS NOT NULL
AND event_name = 'click_tab'
...
(1) Geo, Demographic, Tech 등의 상세한 칼럼들은 굳이 수집하지 않았습니다. 이는 core_fct_events 테이블과 core_dim_users 테이블을 통해 JOIN하도록 관리하는 것이 Star Schema 관점에서 더욱 바람직한 구조이기 때문입니다.
(2) 각 event-specific한 모델 쿼리문 수십 개를 이런 방식으로 생성해두었습니다.
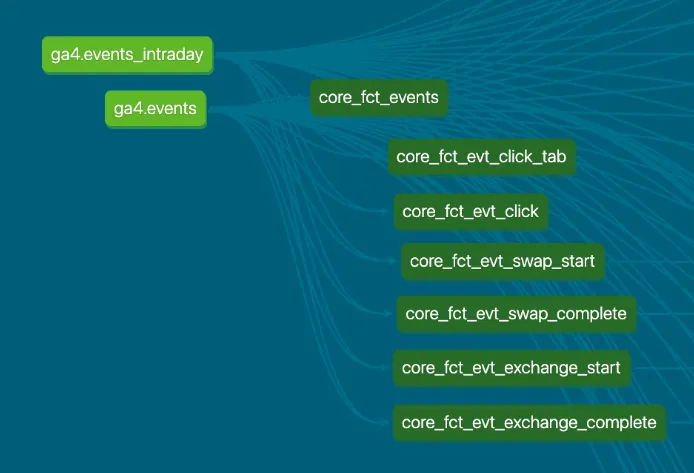
디센트 앱 데이터 웨어하우스 Data Lineage의 일부
한편, core_fct_events 모델과 각 event-specific 모델들의 Configuration은 다음과 같이 구성했습니다.
version: xxx
models:
- name: core_fct_events
description: 전체 이벤트 테이블
meta:
owner: js.kim@iotrust.kr
config:
tags: ["core", "fact"]
materialized: incremental
incremental_strategy: insert_overwrite
on_schema_change: append_new_columns
partition_by:
field: date
data_type: date
granularity: day
time_ingestion_partitioning: true
require_partition_filter: true
copy_partitions: true
columns:
- name: date
description: 이벤트 발생 일자 (NOT NULL)
- name: datetime
description: 이벤트 발생 일시 (NOT NULL)
...
(1) date 칼럼을 파티션 기준으로 정했습니다.
(2) 테이블을 향해 쿼리를 실행할 때 date 파티션 필터를 적용하도록 강제했습니다. (require_partition_filter) 이는 향후 전체 테이블을 읽어오는 등 쿼리 실행 비용을 줄이기 위한 의도적인 장치였어요.
(3) Materialization Strategy는 Incremental (Insert Overwrite) 방식을 적용했습니다.
- 디센트 앱 데이터 웨어하우스는 현재 매 1시간 마다 업데이트 되도록 구축했는데요. 매번 Incremental Update가 발생할 때 각
date별 소스 테이블의 업데이트 유무를 확인하여 업데이트가 된date테이블 데이터를 배치에 적용합니다. - BigQuery의
date파티션 환경에서 Insert Overwrite 방식을 사용하면, 해당date테이블의 데이터를 모두 삭제한 후 다시 전체 데이터를 삽입하는 방식으로 업데이트가 이뤄집니다. 이 덕분에, dbt의 각 모델 쿼리문에 Incremental 전략에 대한 까다로운 조건을 작성하지 않더라도 안정적인 업데이트 전략이 이뤄집니다. (BigQuery와 dbt의 궁합이 잘 맞는 이유 중 하나)
4.4. core_dim_users 테이블 모델 만들기
core_dim_users는 사용자 Dimension Table로서, Star Schema에서 각 Fact Tables가 공유하는 user_pseudo_id의 사용자 속성을 담고 있는 테이블입니다.
WITH
CTE_raw AS (
SELECT
user_pseudo_id,
event_timestamp,
user_first_touch_timestamp,
...
geo.country,
...
FROM
{{ source('ga4', 'events') }}
WHERE
user_pseudo_id IS NOT NULL
...
),
CTE_latest AS (
SELECT
user_pseudo_id,
event_timestamp,
COALESCE(DATE(TIMESTAMP_MICROS(LAST_VALUE(user_first_touch_timestamp IGNORE NULLS) OVER w), 'Asia/Seoul'), DATE('1900-01-01 00:00:00', 'Asia/Seoul')) AS user_first_touch_date,
COALESCE(DATETIME(TIMESTAMP_MICROS(LAST_VALUE(user_first_touch_timestamp IGNORE NULLS) OVER w), 'Asia/Seoul'), DATETIME('1900-01-01 00:00:00', 'Asia/Seoul')) AS user_first_touch_datetime,
CASE
WHEN LAST_VALUE(country IGNORE NULLS) OVER w IS NULL THEN 'UNK'
WHEN LAST_VALUE(country IGNORE NULLS) OVER w = '' THEN 'UNK'
WHEN LAST_VALUE(country IGNORE NULLS) OVER w = '(not set)' THEN 'UNK'
ELSE LAST_VALUE(country IGNORE NULLS) OVER w
END AS country,
ROW_NUMBER() OVER (PARTITION BY user_pseudo_id ORDER BY event_timestamp DESC) AS row_num
FROM
CTE_raw
WINDOW w
AS (PARTITION BY user_pseudo_id ORDER BY event_timestamp ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)
)
SELECT
* EXCEPT (event_timestamp, row_num)
FROM
CTE_latest
WHERE
row_num = 1
(1) 쿼리의 흐름은 크게 다음과 같아요.
- 먼저 소스 테이블에서 전체 사용자 정보를 읽어온 후, 가장 최근 정보들만 기존 테이블에 Insert Overwrite합니다.
(2) SCD(Slowly Changing Dimension) Type 1 방식을 사용하기로 했습니다. 즉, 사용자의 특정 정보에 변동이 생길 때 이를 업데이트 하지만, 예전 정보를 히스토리로 남기지는 않는 방식이에요. 물론, SCD Type 3와 같이 사용자 정보 히스토리 보관 방식도 고민해봤지만, 다음 두 가지 측면에서 적용하지 않기로 했어요.
- 사용자 Dimension의 히스토리까지 확인해야 할 정도로 조직의 데이터 리터러시가 충분히 갖춰지지 않았다고 느꼈어요.
- 게다가 SCD Type 3 방식은 쿼리 비용이 상당히 많이 발생하는 편이므로, 조직의 필요성이 자연스럽게 대두되는 시점에 도입해보기로 판단했어요.
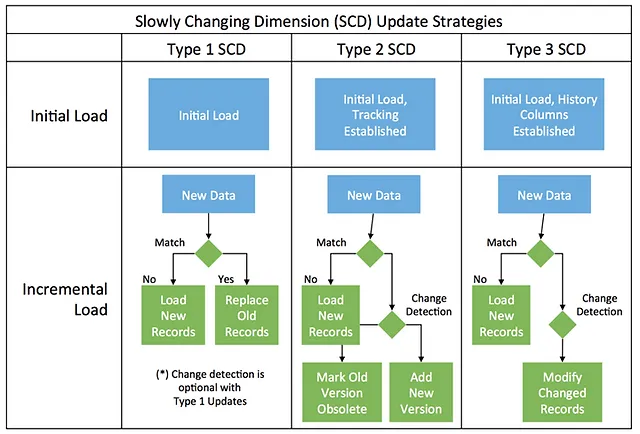
한편, core_dim_users 모델의 Configuration은 다음과 같이 구성했습니다.
version: 1
models:
- name: core_dim_users
description: 사용자 Dimension 테이블
meta:
owner: js.kim@iotrust.kr
config:
tags: ["core", "dim"]
materialized: incremental
incremental_strategy: merge
unique_key: ["user_pseudo_id"]
cluster_by: ["user_pseudo_id"]
on_schema_change: append_new_columns
columns:
- name: user_pseudo_id
description: 사용자 식별자 (PK)
- name: user_first_touch_date
description: 사용자가 처음 앱을 열었거나 사이트를 방문한 일자 (NULL=1900-01-01)
- name: user_first_touch_datetime
description: 사용자가 처음 앱을 열었거나 사이트를 방문한 일시 (NULL=1900-01-01 00:00:00)
...
(1) user_pseudo_id 별로 Clustering함으로써(cluster_by), 향후 JOIN 과정에서 빠르게 Dimension을 읽어올 수 있도록 했습니다.
(2) Materialization Strategy는 Incremental (Merge) 방식을 적용했습니다.
- Incremental 방식을 사용하되,
user_pseudo_id를 Unique Key로 하여 사용자 정보 칼럼들에 변동이 생길 경우 이를 Merge하도록 했어요. 즉, 가장 최근 사용자 정보로만 이루어진 SCD Type 1 방식의 테이블이 완성돼요.
4.5. Incremental Strategy 전략을 위한 Where Statement와 Variables 관리
dbt run을 실행하는 과정에서 한 가지 난점이 있었습니다. Google Analytics 4 Export Tables는 기본적으로 스트리밍으로 Near real-time으로 적재되지만, 일부 칼럼들의 경우 실시간으로 수집되지 않거나, 혹은 값 변동이 발생하거든요. 각 date 파티션 테이블이 최종적으로 완성될 때까지는 안정적으로 3일 정도 소요되는 것을 확인했습니다.
이로 인해, dbt를 통해 데이터 웨어하우스 업데이트 주기인 1시간을 유지하여 데이터 최신성을 유지하기란 쉽지 않았죠. 애초에 소스 테이블에서 불규칙적인 변동이 발생하니까요. 이런 상황에서 최선의 방법은 “변동이 발생한” date 파티션 테이블들을 추려낸 후, 이를 바탕으로 dbt가 처리해야 할 테이블 리스트를 Variables로 먹여주는 방법이었습니다. 즉, 다음과 같습니다.
(1) 각 모델의 Where Statement
...
FROM
{{ source('ga4', 'events_intraday') }}
WHERE
event_date IS NOT NULL
AND event_timestamp IS NOT NULL
AND event_name IS NOT NULL
-- (1) 변수 반영 (Start Date & End Date): 해당 일자 파티션 테이블만 읽어옴
{% if var('start_date', None) is not none and var('end_date', None) is not none %}
AND _table_suffix BETWEEN '' AND ''
{% endif %}
-- (2) 변수 반영 (table_suffixes): 최근 Orchestration 실행 시점 이후 업데이트된 테이블만 읽어옴
{% if var("table_suffixes", None) is not none %}
AND _table_suffix IN ('{{ var("table_suffixes") }}')
{% endif %}
(2) dbt_project.yml 파일의 Variables
...
# Variables
vars:
start_date: # D'CENT App GA4 Export Table Start Date (Default: None)
end_date: # D'CENT App GA4 Export Table End Date (Default: None)
table_suffixes: # D'CENT App GA4 Export Table Suffixes (Default: None)
...
5. 결과
5.1. 쿼리 속도 향상 및 비용 감소
Redash 등을 통한 쿼리 실행 시간이 크게 감소했습니다. 기존에는 쿼리 실행이 15초 이상 소요되었지만, 데이터 웨어하우스 적용 후 고작 5초 내에 완료됩니다.
5.2. 조직의 데이터 접근성 향상6
dbt Docs를 호스팅하여 아래와 같이 각 테이블 명세서를 누구나 쉽게 확인할 수 있습니다. 즉, 사내 구성원들이 쉽고 일관적인 상황에서 쉽게 쿼리를 작성해볼 수 있습니다. 조직의 데이터 접근성이 향상된 것입니다.
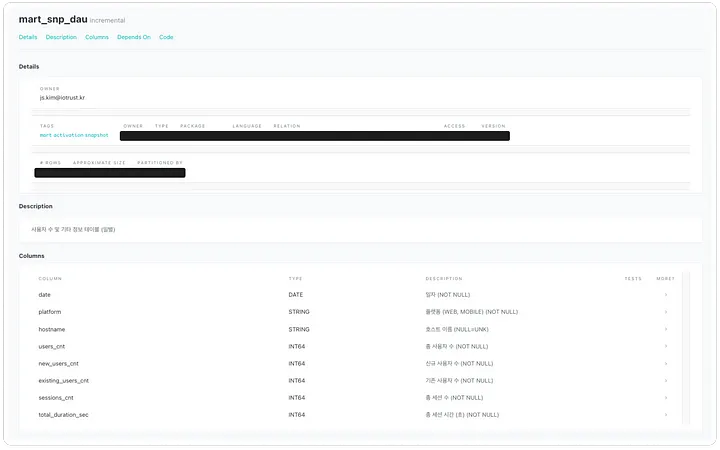
mart_snp_dau테이블 명세서 사례 (일별 사용자 수, 신규 사용자 수, 기존 사용자 수, 총 세션 수, 총 세션 시간)
6. 나가는 글
데이터 웨어하우스와 각 데이터 마트를 구축하는 일은 고되기도 하지만, 상당히 보람 있는 일이기도 합니다. 앞단에서 조금이라도 헝클어지면 조직에서 활용하는 데이터 수치에 심각한 오류가 생기므로 기본적으로 부담이 큰 과업이기도 합니다. 특히, 저는 아이오트러스트에서 데이터를 홀로 책임지고 있기 때문에, 스스로의 실수나 오류가 생기면 이를 피드백할 수 있는 분이 없어요. 그래서 셀프 작업 후 셀프 피드백 시간을 가지며, 복수 개의 자아를 두면서 일을 하기도 해요.🙄
하지만 데이터 웨어하우스를 통해 뒷단에서 동료들이 데이터를 쉽고 편하게 확인하는 모습을 보면 상당히 뿌듯하고, 그만큼 데이터에 대한 오너십이 커집니다. 그에 따라 조직의 데이터 기반 의사결정이 제대로 이루어져가는 모습에 더욱 애착이 많아지기도 하구요.
앞으로는 프로덕트 내부 데이터가 아니라, 프로덕트 외부 데이터를 활용하는 환경에 집중해보려고 합니다. 이를 통해 프로덕트의 내/외부 데이터를 함께 활용할 수 있는 환경이 이루어지길 바라봅니다.