
GA4-based Data Warehouse Implementation Review
“This article shares the process and outcomes of building a data warehouse to efficiently utilize Google Analytics 4 (GA4) data. Previously, queries were executed directly on the GA4 Export Table, but issues such as schema complexity, slow query execution times, and high costs necessitated a transition to a data mart. By implementing an Incremental Strategy using dbt, we optimized performance, resulting in significantly improved query speeds, reduced costs, and enhanced data accessibility within the organization, enabling more efficient data utilization.”
Table of Contents
- Introduction
- Diagnosing the Problem
- 2.1. Complex Schema of the Source Table
- 2.2. Slow Query Execution Time and High Query Costs
- Solution: Building a Data Warehouse
- 3.1. Simplified Schema for Each Data Mart Table
- 3.2. Faster Query Execution and Reduced Costs
- Implementation of the Data Warehouse
- 4.1. Data Lineage Preview of the Data Warehouse
- 4.2. Creating the
core_fct_eventsTable Model - 4.3. Creating Event-Specific Table Models
- 4.4. Creating the
core_dim_usersTable Model - 4.5. Managing Where Statements and Variables for Incremental Strategy
- Results
- 5.1. Improved Query Speed and Reduced Costs
- 5.2. Enhanced Organizational Data Accessibility
- Conclusion
1. Introduction
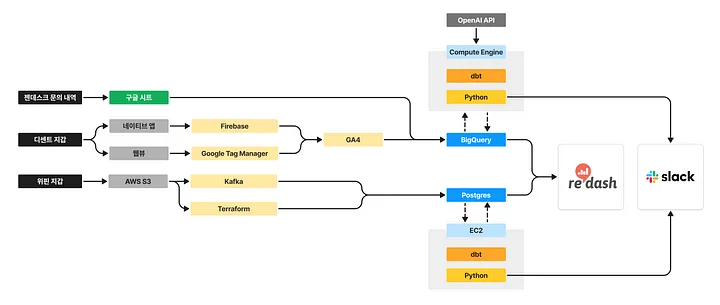
Simplified IoTrust Data Pipeline
Our company operates the B2C product D’Cent Wallet and the B2B2C product Wepen Wallet. Among them, the D’Cent Wallet primarily loads data into BigQuery via Google Analytics 4!
Many startups directly execute queries on the Google Analytics 4 Export Table stored in BigQuery. However, this “source table-dependent” query execution approach can lead to significant issues over time, including increased query costs and execution times.
To overcome this, I implemented a “rarely seen” GA4-based data warehouse structure. This article shares my experience with this approach.
2. Diagnosing the Problem
2.1. Complex Schema of the Source Table
The Google Analytics 4 Export Table streamed to BigQuery is designed with flexible structural expansion in mind. As a result, event parameters and purchase product information are stored in RECORD types. This design choice by Google leverages a columnar database structure to reduce storage costs.
For example, event_params is stored in a key-value format similar to JSON, making it challenging for those unfamiliar with this structure to write queries.
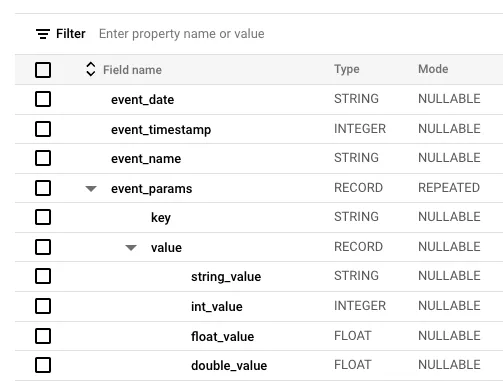
GA4 Source Table Schema (Public Sample Table)
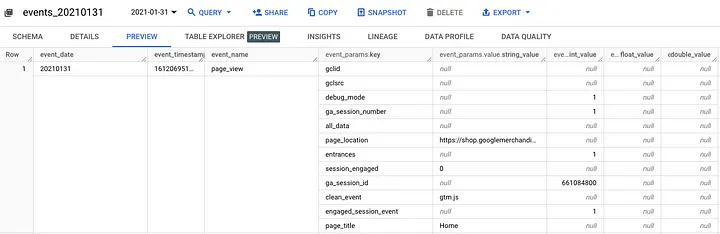
GA4 Source Table Preview (Public Sample Table)
Even extracting a simple page visit count requires writing a complex query, as shown below. This poses a steep learning curve for new users.
SELECT
event_date,
COUNT(DISTINCT ga_session_id) AS sessions_cnt,
COUNT(DISTINCT user_pseudo_id) AS users_cnt
FROM
`events_*`
WHERE
_table_suffix BETWEEN '20240101' AND '20241231'
AND event_name = 'page_view'
AND (SELECT value.string_value FROM UNNEST (event_params) WHERE key = 'page_location') LIKE '%store.dcentwallet.com/pages/dcent-biometric-crypto-wallet%'
GROUP BY
1
ORDER BY
1
;
A simplified table schema is needed to allow users to write queries more easily.
2.2. Slow Query Execution Time and High Query Costs
Executing queries directly on the source table becomes increasingly inefficient over time, leading to slow execution times and rapidly rising query costs.
For non-technical colleagues who only consume dashboards, long update times significantly hinder data usability. A somewhat extreme quote captures this challenge well:
“If a dashboard update takes longer than 5 seconds, marketers and designers will immediately disengage. Optimizing queries is critical to maintaining data usability.”
3. Solution: Building a Data Warehouse
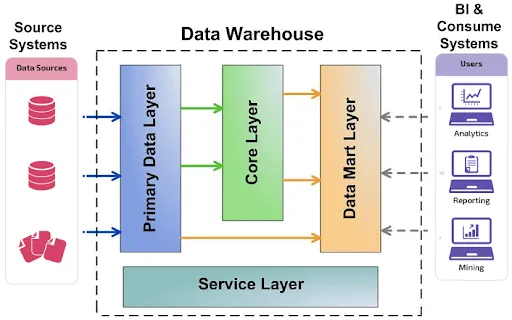
Implementing a data warehouse dramatically resolves the aforementioned issues.
3.1. Simplified Schema for Each Data Mart Table
By simplifying the structure of each data mart and its tables, colleagues can execute queries with ease. This reduces dependence on data analysts and analytics engineers, creating a self-service environment for data queries.
3.2. Faster Query Execution and Reduced Costs
Data mart tables are structured with only the necessary columns and rows, making them significantly smaller than source tables. Running queries on data marts results in drastically improved execution times and lower costs.
4. Implementation of the Data Warehouse
4.1. Data Lineage Preview of the Data Warehouse
The core layer of the D’Cent App data warehouse is structured as follows, forming a star schema from the source tables ga4.events and ga4.events_intraday.
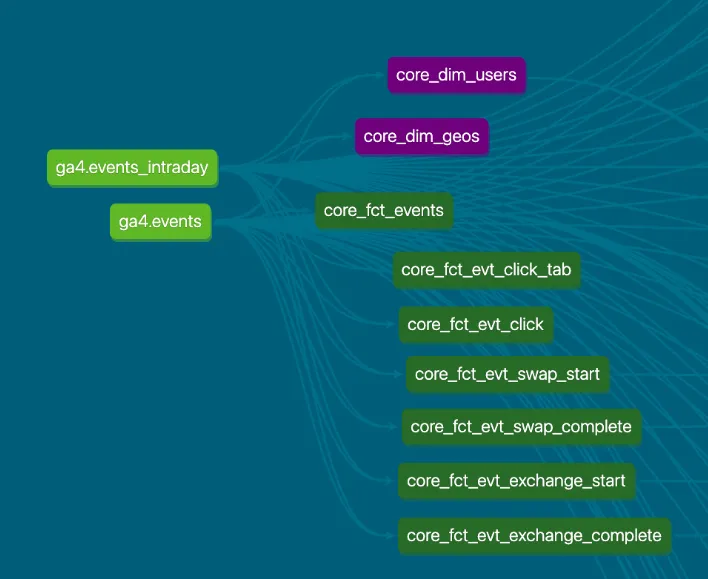
Partial View of D’Cent App Data Warehouse Data Lineage
4.2. Creating the core_fct_events Table Model
The foundational fact table, containing all recorded events, was created while excluding unique event parameters. The goal was to include as much information as possible.
SELECT
DISTINCT
PARSE_DATE('%Y%m%d', event_date) AS date,
DATETIME(TIMESTAMP_MICROS(event_timestamp), 'Asia/Seoul') AS datetime,
COALESCE(user_pseudo_id, 'UNK') AS user_pseudo_id,
COALESCE((SELECT value.int_value FROM UNNEST (event_params) WHERE key = 'ga_session_id'), -1) AS ga_session_id,
COALESCE((SELECT value.int_value FROM UNNEST (event_params) WHERE key = 'ga_session_number'), -1) AS ga_session_number,
event_name,
COALESCE(device.web_info.hostname, 'UNK') AS hostname,
COALESCE((SELECT value.string_value FROM UNNEST (event_params) WHERE key = 'page_location'), 'UNK') AS page_location_full,
COALESCE((SELECT FROM UNNEST (event_params) WHERE key = 'page_location'), 'UNK') AS page_location,
COALESCE((SELECT value.string_value FROM UNNEST (event_params) WHERE key = 'page_title'), 'UNK') AS page_title,
COALESCE(
LOWER((SELECT value.string_value FROM UNNEST (user_properties) WHERE key = 'xxx')),
LOWER(CAST((SELECT value.double_value FROM UNNEST (user_properties) WHERE key = 'xxx') AS STRING)),
LOWER(CAST((SELECT value.float_value FROM UNNEST (user_properties) WHERE key = 'xxx') AS STRING)),
LOWER(CAST((SELECT value.int_value FROM UNNEST (user_properties) WHERE key = 'xxx') AS STRING)),
'UNK'
) AS xxx,
COALESCE(platform, 'UNK') AS platform,
COALESCE(device.operating_system, 'UNK') AS device_os,
COALESCE(device.category, 'UNK') AS device_category,
COALESCE(app_info.version, 'UNK') AS app_version,
CASE
WHEN geo.continent IS NULL THEN 'UNK'
WHEN geo.continent = '' THEN 'UNK'
WHEN geo.continent = '(not set)' THEN 'UNK'
ELSE geo.continent
END AS continent,
CASE
WHEN geo.country IS NULL THEN 'UNK'
WHEN geo.country = '' THEN 'UNK'
WHEN geo.country = '(not set)' THEN 'UNK'
ELSE geo.country
END AS country,
COALESCE(traffic_source.name, 'UNK') AS first_utm_campaign,
COALESCE(traffic_source.medium, 'UNK') AS first_utm_medium,
COALESCE(traffic_source.source, 'UNK') AS first_utm_source,
COALESCE((SELECT value.string_value FROM UNNEST (event_params) WHERE key = 'campaign_id'), 'UNK') AS event_utm_campaign_id,
COALESCE((SELECT value.string_value FROM UNNEST (event_params) WHERE key = 'campaign'), 'UNK') AS event_utm_campaign,
COALESCE((SELECT value.string_value FROM UNNEST (event_params) WHERE key = 'medium'), 'UNK') AS event_utm_medium,
COALESCE((SELECT value.string_value FROM UNNEST (event_params) WHERE key = 'source'), 'UNK') AS event_utm_source,
COALESCE((SELECT value.string_value FROM UNNEST (event_params) WHERE key = 'term'), 'UNK') AS event_utm_term,
COALESCE((SELECT value.string_value FROM UNNEST (event_params) WHERE key = 'content'), 'UNK') AS event_utm_content,
...
FROM
WHERE
event_date IS NOT NULL
AND event_timestamp IS NOT NULL
AND event_name IS NOT NULL
...
(1) In the GA4 Export Table, identical events are often collected twice in succession for unknown reasons. This issue occurs frequently, particularly depending on the structure of the app’s development source code. Since this can lead to data distortion during the aggregation process, we ensured that duplicates are always removed using DISTINCT, even at the cost of additional computation.
(2) To simplify model queries, we used Select Subqueries with UNNEST for event parameters and user properties.
(3) We established the following null-handling rules to prevent data distortion during the aggregation process:
- String: “UNK” (unknown)
- Number: -1
- Date: “1900-01-01”
(4) Rows without event_date, event_timestamp, or event_name values were excluded from the model. If any of these three values are unknown, they provide no meaningful value as data.
(5) Handling the page_location field is time-consuming for query writers due to varying query elements in page URLs. To address this, we defined a custom dbt macro function named clean_url to ensure a clean and standardized output.
- Example of the
clean_urlmacro:
{% macro clean_url(column_name) %}
REPLACE(
REGEXP_REPLACE(
REGEXP_REPLACE(
LOWER({{ column_name }}),
r'(\?.*)$',
''
),
r'/$',
''
),
'https://',
''
)
{% endmacro %}
4.3. Creating Event-Specific Table Models
As previously mentioned, each event has a completely different parameter structure. We needed to build independent event parameter information for each event. If the organization’s event taxonomy changes and new parameters are collected, applying these changes to the entire data warehouse would significantly increase query costs. By managing event-specific models, we ensured that only the necessary event-specific tables are affected, minimizing the impact of changes in the source table.
For example, the following model query defines core_fct_evt_click_tab, which includes only the click_tab event and the to_tab_name parameter.
SELECT
DISTINCT
PARSE_DATE('%Y%m%d', event_date) AS date,
DATETIME(TIMESTAMP_MICROS(event_timestamp), 'Asia/Seoul') AS datetime,
COALESCE(user_pseudo_id, 'UNK') AS user_pseudo_id,
COALESCE((SELECT value.int_value FROM UNNEST (event_params) WHERE key = 'ga_session_id'), -1) AS ga_session_id,
COALESCE((SELECT value.int_value FROM UNNEST (event_params) WHERE key = 'ga_session_number'), -1) AS ga_session_number,
COALESCE(device.web_info.hostname, 'UNK') AS hostname,
COALESCE((SELECT value.string_value FROM UNNEST (event_params) WHERE key = 'page_location'), 'UNK') AS page_location_full,
COALESCE((SELECT {{ clean_url('value.string_value') }} FROM UNNEST (event_params) WHERE key = 'page_location'), 'UNK') AS page_location,
COALESCE((SELECT value.string_value FROM UNNEST (event_params) WHERE key = 'page_title'), 'UNK') AS page_title,
COALESCE((SELECT {{ clean_url('value.string_value') }} FROM UNNEST (event_params) WHERE key = 'to_tab_name'), 'UNK') AS to_tab_name,
...
FROM
{{ source('ga4', 'events') }}
WHERE
event_date IS NOT NULL
AND event_timestamp IS NOT NULL
AND event_name = 'click_tab'
...
(1) We did not collect detailed columns such as Geo, Demographic, and Tech data. From a Star Schema perspective, managing these through core_fct_events and core_dim_users tables via JOIN operations is a more optimal approach.
(2) We created dozens of event-specific model queries in this manner.

A section of the D’CENT App Data Warehouse Data Lineage
Meanwhile, the configuration for core_fct_events and each event-specific model is structured as follows:
version: xxx
models:
- name: core_fct_events
description: Main event table
meta:
owner: Joshua Kim
config:
tags: ["core", "fact"]
materialized: incremental
incremental_strategy: insert_overwrite
on_schema_change: append_new_columns
partition_by:
field: date
data_type: date
granularity: day
time_ingestion_partitioning: true
require_partition_filter: true
copy_partitions: true
columns:
- name: date
description: Event occurrence date (NOT NULL)
- name: datetime
description: Event occurrence timestamp (NOT NULL)
...
(1) The date column was set as the partitioning key.
(2) Queries were required to include a partition filter on date (require_partition_filter) to prevent full table scans and reduce query execution costs.
(3) The materialization strategy was set to Incremental (Insert Overwrite).
- The D’CENT App data warehouse updates every hour. Each incremental update checks whether the source table for each
datepartition has been updated and applies only the updated partitions. - In BigQuery’s
datepartition environment, using Insert Overwrite removes all data for a specificdatepartition before reinserting the updated data. This allows for a stable update strategy without complex incremental logic in dbt models.
4.4. Creating the core_dim_users Table Model
The core_dim_users table serves as a user dimension table, containing user attributes associated with user_pseudo_id, which is shared among fact tables in the Star Schema.
WITH
CTE_raw AS (
SELECT
user_pseudo_id,
event_timestamp,
user_first_touch_timestamp,
...
geo.country,
...
FROM
{{ source('ga4', 'events') }}
WHERE
user_pseudo_id IS NOT NULL
...
),
CTE_latest AS (
SELECT
user_pseudo_id,
event_timestamp,
COALESCE(DATE(TIMESTAMP_MICROS(LAST_VALUE(user_first_touch_timestamp IGNORE NULLS) OVER w), 'Asia/Seoul'), DATE('1900-01-01 00:00:00', 'Asia/Seoul')) AS user_first_touch_date,
COALESCE(DATETIME(TIMESTAMP_MICROS(LAST_VALUE(user_first_touch_timestamp IGNORE NULLS) OVER w), 'Asia/Seoul'), DATETIME('1900-01-01 00:00:00', 'Asia/Seoul')) AS user_first_touch_datetime,
CASE
WHEN LAST_VALUE(country IGNORE NULLS) OVER w IS NULL THEN 'UNK'
WHEN LAST_VALUE(country IGNORE NULLS) OVER w = '' THEN 'UNK'
WHEN LAST_VALUE(country IGNORE NULLS) OVER w = '(not set)' THEN 'UNK'
ELSE LAST_VALUE(country IGNORE NULLS) OVER w
END AS country,
ROW_NUMBER() OVER (PARTITION BY user_pseudo_id ORDER BY event_timestamp DESC) AS row_num
FROM
CTE_raw
WINDOW w
AS (PARTITION BY user_pseudo_id ORDER BY event_timestamp ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)
)
SELECT
* EXCEPT (event_timestamp, row_num)
FROM
CTE_latest
WHERE
row_num = 1
(1) The main query flow follows these steps:
- First, the source table retrieves all user information.
- Then, the most recent information is inserted into the existing table using Insert Overwrite.
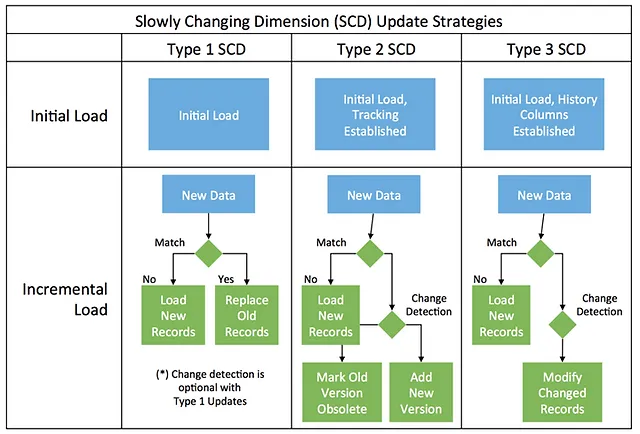
(2) We implemented Slowly Changing Dimension (SCD) Type 1, updating user attributes without maintaining historical records. While we considered SCD Type 3 for tracking historical changes, we decided against it due to:
- The organization’s insufficient data literacy to justify tracking user history.
- The high query costs associated with SCD Type 3.
Meanwhile, the configuration of the core_dim_users model is structured as follows:
version: 1
models:
- name: core_dim_users
description: User Dimension 테이블
meta:
owner: Joshua Kim
config:
tags: ["core", "dim"]
materialized: incremental
incremental_strategy: merge
unique_key: ["user_pseudo_id"]
cluster_by: ["user_pseudo_id"]
on_schema_change: append_new_columns
columns:
- name: user_pseudo_id
description: User Identifier (PK)
- name: user_first_touch_date
description: The date when the user first opened the app or visited the website. (NULL=1900-01-01)
- name: user_first_touch_datetime
description: The timestamp when the user first opened the app or visited the website. (NULL=1900-01-01 00:00:00)
...
(1) By clustering based on user_pseudo_id (cluster_by), we enable faster retrieval of dimension data during JOIN operations in the future.
(2) The materialization strategy is set to Incremental (Merge).
- The Incremental approach is applied, with
user_pseudo_idas the unique key, ensuring that any changes in user information columns are merged accordingly. This results in a table structured as an SCD Type 1 model, where only the most recent user information is retained.
4.5. Managing Where Statements and Variables for the Incremental Strategy
One challenge encountered during the dbt run execution process was that Google Analytics 4 Export Tables are ingested in near real-time through streaming. However, certain columns are not collected in real-time, or their values may fluctuate. We observed that it takes approximately three days for each date-partitioned table to be fully completed.
Due to this, maintaining a one-hour update cycle for the data warehouse via dbt to ensure data freshness was challenging. Since the source table experiences irregular updates, the best approach was to identify date-partitioned tables where changes occurred and use them as variables for dbt processing. This approach can be summarized as follows:
(1) Where Statement for Each Model
...
FROM
{{ source('ga4', 'events_intraday') }}
WHERE
event_date IS NOT NULL
AND event_timestamp IS NOT NULL
AND event_name IS NOT NULL
-- (1) Applying Variables (Start Date & End Date): Reads only the relevant date-partitioned tables
{% if var('start_date', None) is not none and var('end_date', None) is not none %}
AND _table_suffix BETWEEN '' AND ''
{% endif %}
-- (2) Applying Variables (table_suffixes): Reads only tables updated since the last orchestration run
{% if var("table_suffixes", None) is not none %}
AND _table_suffix IN ('{{ var("table_suffixes") }}')
{% endif %}
(2) Variables in the dbt_project.yml File
...
# Variables
vars:
start_date: # D'CENT App GA4 Export Table Start Date (Default: None)
end_date: # D'CENT App GA4 Export Table End Date (Default: None)
table_suffixes: # D'CENT App GA4 Export Table Suffixes (Default: None)
...
5. Results
5.1. Improved Query Performance and Cost Reduction
Query execution times in Redash and other BI tools have significantly decreased. Previously, queries took over 15 seconds to execute, but after integrating the data warehouse, execution now completes within just 5 seconds.
5.2. Enhanced Data Accessibility for the Organization
By hosting dbt Docs, anyone can easily access table specifications, as shown below. This enables internal team members to write queries in a more structured and consistent manner, improving overall data accessibility within the organization.
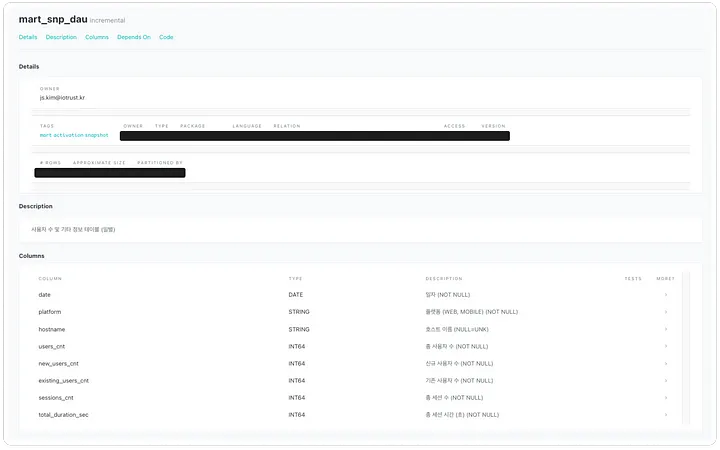
Example of
mart_snp_dautable documentation (Daily Active Users, New Users, Returning Users, Total Sessions, Total Session Duration)
6. Conclusion
Building a data warehouse and its associated data marts is a challenging yet highly rewarding task. Even minor issues at the early stages can lead to significant errors in the data used across the organization, making this a highly responsible role. Since I am solely responsible for data management at IoTrust, there is no one to provide feedback on my mistakes. As a result, I adopt a self-review process, essentially working with multiple versions of myself.🙄
However, seeing my colleagues access and utilize data easily through the data warehouse is incredibly fulfilling. It strengthens my sense of ownership over data, and I become even more invested in ensuring that the organization’s data-driven decision-making is executed properly.
Moving forward, I plan to focus not just on internal product data but also on leveraging external product data. My goal is to create an environment where both internal and external data can be utilized together to drive better insights.
Published by Joshua Kim
