Airflow 도입 후기
“Airflow 도입을 통해 사내 데이터 알림 시스템을 효율적으로 관리하고자 기존 Python 기반 세션 방식에서 벗어나 DAG 기반 워크플로우를 구축했습니다. Docker Compose를 활용해 로컬 및 VM 환경에서 Airflow를 설정하고, Slack 알림을 포함한 다양한 데이터 파이프라인을 자동화했습니다. 이를 통해 유지보수 부담을 줄이고, 안정성을 높이며, 확장 가능한 데이터 처리 환경을 마련할 수 있었습니다.”
목차
- 도입 배경
- 도입 후기
- 2.1. 작업 계획
- 2.2. 로컬 환경 세팅
- 2.3. VM Instance 환경 세팅
- 2.4. DAG 만들기
- 앞으로의 과제
1. 도입 배경
저는 아이오트러스트에서 데이터 엔지니어 포지션으로 근무하며, 아래와 같이 주로 애널리틱스 엔지니어링 업무에 집중하고 있어요.
- (1) 데이터 웨어하우스 & 데이터 마트 설계 및 개발
- (2) BI 대시보드
- (3) Ad-hoc 데이터 알림 봇 개발
- (4) 이벤트 택소노미 설계 + 정의서 관리
- (5) (Finance/HR/CX) 업무 자동화 환경 구축
그런데, 시간이 흐를수록 “(3) Ad-hoc 데이터 알림 봇 개발” 역할에 문제가 발생하기 시작했어요. 동료들이 적시에 중요한 핵심 지표를 슬랙으로 빠르게 확인할 수 있도록 지원하는 과정에서, 서서히 Python 파일이 많아졌고 관리 리소스도 제법 늘어나게 된 것이죠.
구체적으로는, 아래와 같이 tmux를 통해 세션 레벨에서 각 Python 파일을 직접 실행하여 모든 슬랙 알림을 관리하고 있었어요. tmux는 단일 터미널에서 여러 세션을 독립적으로 관리할 수 있도록 해주는 오픈소스 터미널 자동화 도구예요. (Wikipedia)
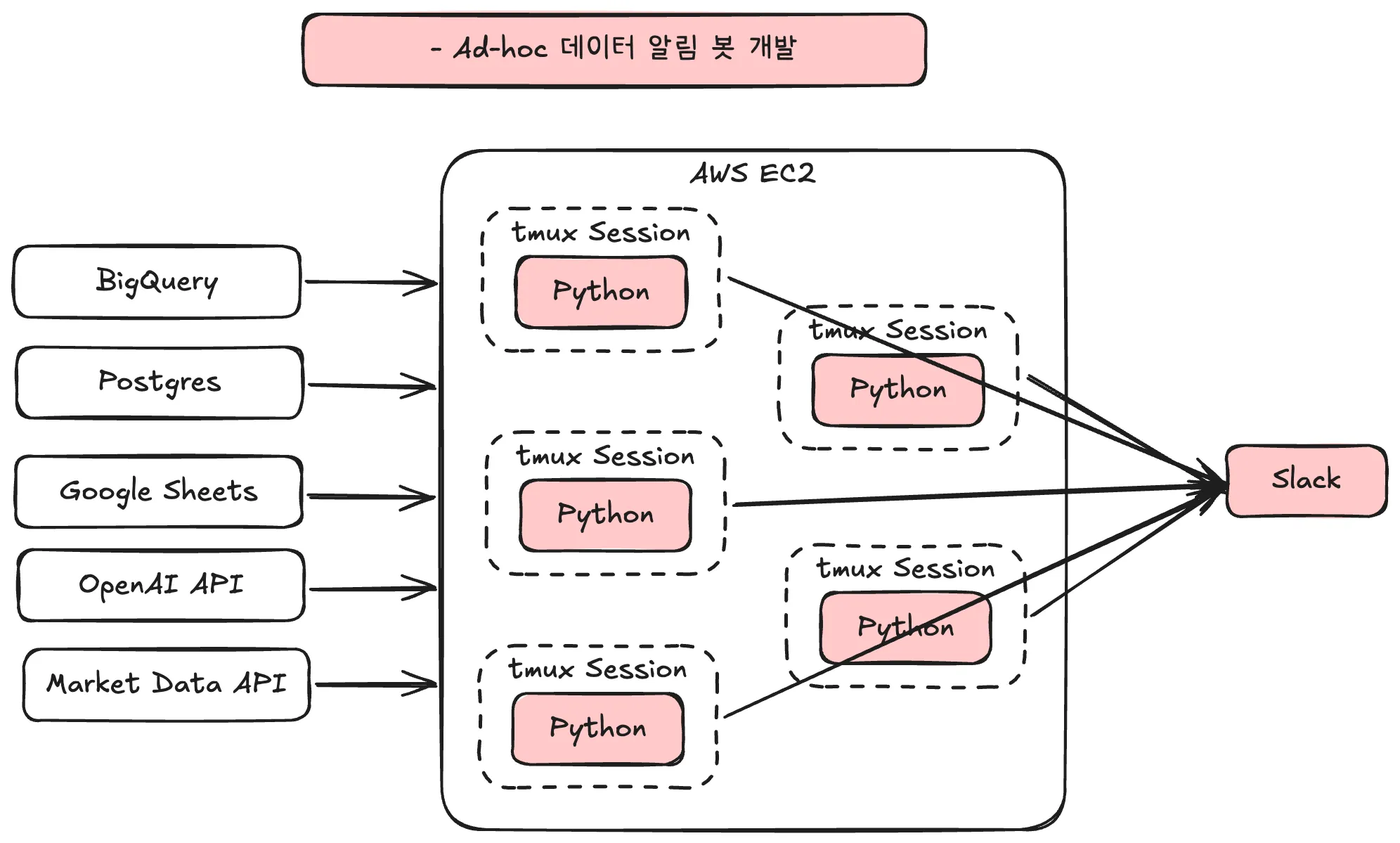
점차 Python 파일이 많아지고 복잡해지면서 구체적으로 다음과 같은 문제가 발생하기 시작했어요.
(1) 유지보수 부담이 늘어났어요.
Python 파일의 오류가 발생하면 실행이 즉시 중단되어 디버깅이 완료되기 전까지는 동료들이 알림을 받을 수 없었어요. 작업 재시도 기능이 없었기 때문이죠.
또한, 디버깅 과정에서 제법 많은 시간을 허비했어요. 의존성이 있는 각 파이프라인 단계를 main() 함수 하나로 관리하다 보니, 정확한 실패 원인을 찾는 데 상당한 시간이 소요되었던 것이죠. 그러다보니 중요한 일에 몰입하지 못하고 업무가 산만해지기 쉬웠죠.
(2) 세션 기반 관리의 안정성이 부족했어요.
서버 재부팅이나 네트워크 문제로 인해 작업이 중단될 여지가 높았고, 실제로 알 수 없는 이유로 세션이 모두 종료되어 복구 작업을 해야 했던 적도 있었어요.
또한, 각 세션이 동일한 환경을 공유하기 때문에 Python Venv를 사용하더라도 의도치 않은 충돌이나 종속성 문제가 발생할 여지가 있었어요.
이런 이유로 Airflow를 통한 워크플로우 관리 필요성이 점차 커지게 되었어요.
- 컨테이너만 재시작하면 각 작업을 자동으로 복구할 수 있어요.
- 각 작업별로 독립된 환경을 제공해요.
- 지속적으로 작업을 확장할 수 있어요.
- 웹서버 UI를 통해 관리를 용이하게 할 수 있어요.
사실, “Ad-hoc 데이터 알림 봇 개발” 업무 초기에 이미 Airflow 도입을 적극적으로 검토했었습니다. 하지만 당시 워크플로우의 규모가 매우 작았기 때문에, YAGNI 원칙에 따라 굳이 도입할 필요가 없다고 판단했죠.
YAGNI는 “You Aren’t Gonna Need It”의 준말로, 필요하지 않은 기능이나 복잡성을 미리 추가하지 말라는 애자일 소프트웨어 개발의 핵심 원칙 중 하나입니다. 당시에는 현재 요구 사항을 충족하는 적절한 수준에서만 워크플로우 환경을 구축하는 것이 중요하다고 생각해, 세션 기반 관리 방식을 선택했어요.
그러나 워크플로우 규모가 점차 커지면서 세션 관리 방식에서 발생하는 리소스 낭비와 비효율성이 눈에 띄게 늘어났어요. 이에 따라, Airflow 도입이 필요하다고 판단하게 되었습니다.
2. 도입 후기
2.1. 작업 계획
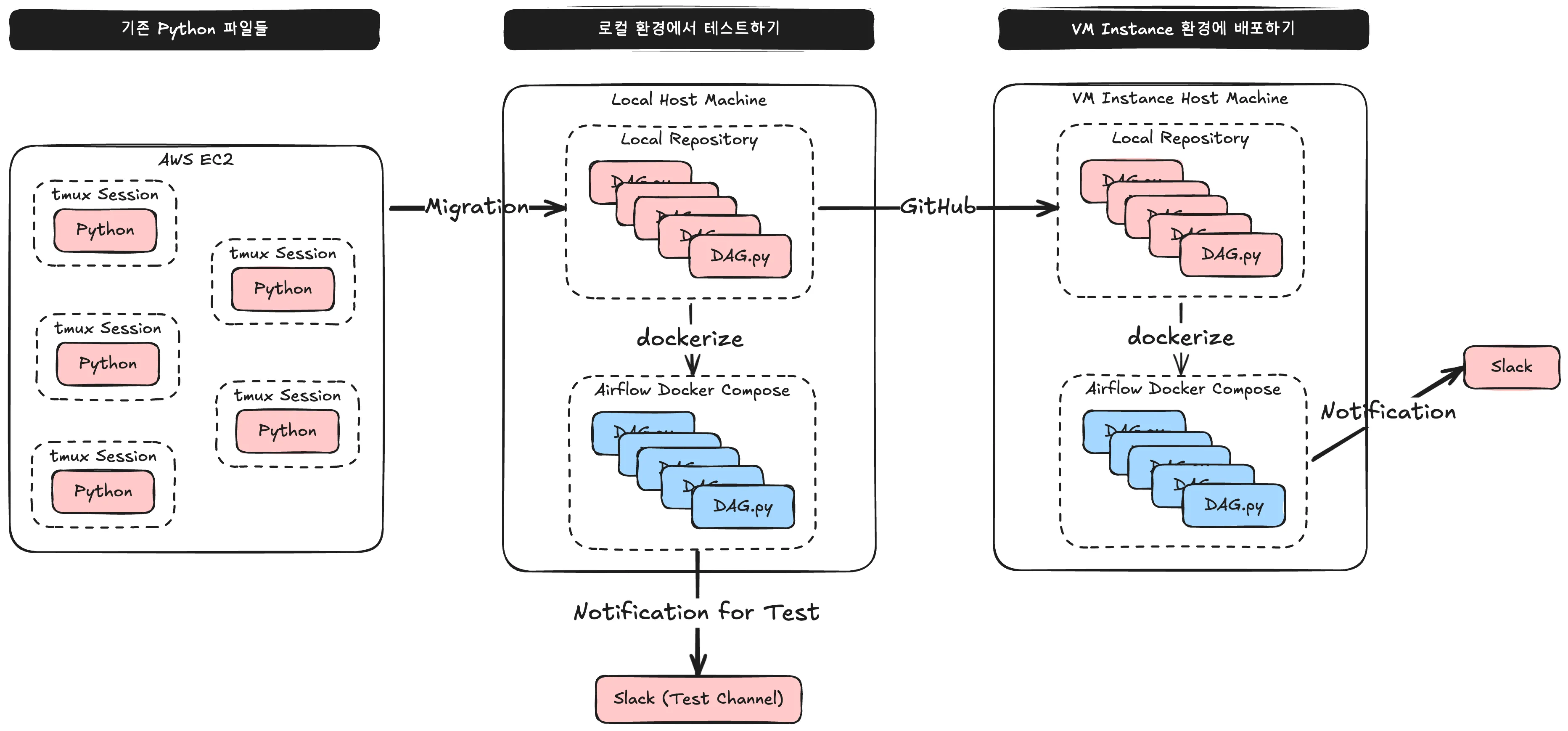
먼저 위 그림과 같이 계획을 세웠어요.
(1) 기존 Python 파일들을 DAG 포맷에 맞게 코드를 수정합니다.
(2) 로컬 환경에서 Airflow 프로젝트를 Docker Compose로 빌드하여, 알림이 슬랙 테스트 채널에 제대로 전송되는지 확인합니다.
(3) VM Instance 환경에서도 Airflow 프로젝트를 Docker Compose로 빌드하여, 최종적으로 알림 환경을 배포합니다.
2.2. 로컬 환경 세팅
(0) 기본적으로 Docker가 설치되어 있어야 해요.
- 저는 Docker Desktop 앱을 설치하는 방향으로 준비했어요. 정확한 설치 방법은 이 문서를 참고해주세요.
(1) Python Venv를 생성했어요.
python -m venv venv
source venv/bin/activate
(2) airflow 이름의 디렉토리에서 아래 명령어를 통해 Airflow 이미지를 로드했어요. (docker-compose.yaml 파일이 생성될 거예요.)
curl -LfO 'https://airflow.apache.org/docs/apache-airflow/2.9.1/docker-compose.yaml'
(3) dags, logs, plugins 하위 디렉토리를 생성하고, AIRFLOW_UID 환경 변수를 지닌 .env 파일을 생성했어요.
mkdir -p ./dags ./logs ./plugins
echo -e "AIRFLOW_UID=$(id -u)" > .env
(4) 아래 내용을 지닌 Dockerfile 파일을 생성했어요.
# First-time build can take upto 10 mins.
FROM apache/airflow:2.9.1
ENV AIRFLOW_HOME=/opt/airflow
USER root
RUN apt-get update -qq && apt-get install vim -qqq
# git gcc g++ -qqq
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Ref: https://airflow.apache.org/docs/docker-stack/recipes.html
SHELL ["/bin/bash", "-o", "pipefail", "-e", "-u", "-x", "-c"]
ARG CLOUD_SDK_VERSION=322.0.0
ENV GCLOUD_HOME=/home/google-cloud-sdk
ENV PATH="${GCLOUD_HOME}/bin/:${PATH}"
RUN DOWNLOAD_URL="https://dl.google.com/dl/cloudsdk/channels/rapid/downloads/google-cloud-sdk-${CLOUD_SDK_VERSION}-linux-x86_64.tar.gz" \
&& TMP_DIR="$(mktemp -d)" \
&& curl -fL "${DOWNLOAD_URL}" --output "${TMP_DIR}/google-cloud-sdk.tar.gz" \
&& mkdir -p "${GCLOUD_HOME}" \
&& tar xzf "${TMP_DIR}/google-cloud-sdk.tar.gz" -C "${GCLOUD_HOME}" --strip-components=1 \
&& "${GCLOUD_HOME}/install.sh" \
--bash-completion=false \
--path-update=false \
--usage-reporting=false \
--quiet \
&& rm -rf "${TMP_DIR}" \
&& gcloud --version
WORKDIR $AIRFLOW_HOME
COPY scripts scripts
RUN chmod +x scripts
USER $AIRFLOW_UID
(5) 아래 내용을 지닌 requirements.txt 파일을 생성했어요.
apache-airflow-providers-google
pyarrow
(6) docker-compose.yaml 파일에서 다음 항목들을 추가/편집했어요.
/keys: 구글 클라우드 서비스 계정 json key 파일을 보관하는 용도.env: Airflow Admin 로그인 정보와 슬랙 API 토큰을 보관하는 용도
x-airflow-common:
...
environment:
...
AIRFLOW__CORE__LOAD_EXAMPLES: 'false' # 샘플 DAG가 생성되지 않도록 했어요.
...
GOOGLE_APPLICATION_CREDENTIALS: /keys/airflow_credentials.json # 구글 클라우드 서비스 계정 json key 파일의 경로를 입력했어요.
AIRFLOW_CONN_GOOGLE_CLOUD_DEFAULT: 'google-cloud-platform://?extra__google_cloud_platform__key_path=/keys/airflow_credentials.json' # 여기도 마찬가지에요.
GCP_PROJECT_ID: 'gcp_project_id' # 구글 클라우드 프로젝트 ID를 입력했어요.
AIRFLOW_CONN_SLACK_DEFAULT: 'slack://:${SLACK_TOKEN}@' # 슬랙 API 토큰은 .env 파일에서 관리했어요.
...
volumes:
...
- ./keys:/keys:ro # 구글 클라우드 서비스 계정 json key 파일이 담긴 /keys 디렉토리를 Docker 상에 매핑해줬어요.
...
services:
...
airflow-init:
...
environment:
...
_AIRFLOW_WWW_USER_USERNAME: ${_AIRFLOW_WWW_USER_USERNAME} # Airflow Webserver 로그인 정보는 .env 파일에서 관리했어요.
_AIRFLOW_WWW_USER_PASSWORD: ${_AIRFLOW_WWW_USER_PASSWORD} # Airflow Webserver 로그인 정보는 .env 파일에서 관리했어요.
...
(7) Docker Compose를 빌드하고, Initialize Airflow 했어요.
docker-compose build
docker-compose up airflow-init
(8) 마지막으로 Docker Compose를 실행했어요.
docker-compose up -d
docker-compose ps
(9) 브라우저에서 Airflow Webserver에 접속하여 로그인했어요.
1) http://0.0.0.0:8080 로 접속해요.
2) docker-compose.yaml에서 설정했던 아래의 환경 변수로 로그인하면 돼요.
- _AIRFLOW_WWW_USER_USERNAME
- _AIRFLOW_WWW_USER_PASSWORD
(10) airflow 디렉토리에 Initialize Git을 한 후, GitHub Remote Repo에 연동했어요. (물론, 연동하면 안되는 파일들은 .gitignore에 리스트업했어요.)
git init
git remote add origin https://github.com/.../airflow.git
git branch -m main
git add .
git commit -m "created airflow project"
git push -u origin main
2.3. VM Instance 환경 세팅
(1) 방화벽 규칙을 생성했어요. (VM Instance에서 운영 중인 Airflow Webserver에 사내 로컬에서도 접속할 수 있도록 해야 하거든요.)
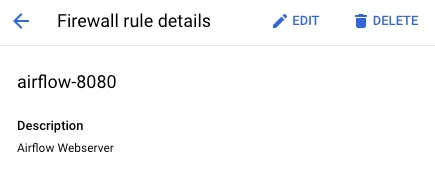
- 방향: Ingress
- 대상 태그: airflow (원하는 이름으로 적으셔도 돼요.)
- 소스 필터 > IP 범위: 사내 IP Address Range를 입력했어요.
- 프로토콜 및 포트: tcp-8080 (Webserver는 8080 포트를 통해 Host Machine과 소통하기 때문이에요.
docker-compose.yaml파일에서 포트를 수정할 수도 있어요.)
(2) airflow 이름의 VM Instance를 만들었어요.
- Machine: E2 시리즈 중 vCPU 2개 이상, 메모리 8GB 이상을 추천해요. (메모리 4GB를 선택하면 서버가 네트워크 트래픽을 견디지 못해 쉽게 먹통이 될 거예요.)
- OS & Storage: OS는 Debian, 스토리지 사이즈는 10GB를 선택했어요.
- 방화벽: HTTP & HTTPS 트래픽을 “사용”으로 설정한 후, 방화벽 규칙에서 생성했던 태그인
airflow를 입력했어요.
(3) 로컬 환경에서 세팅한 것과 마찬가지로 Docker를 설치하고, Python Venv를 생성했어요.
- 2.2. 로컬 환경 세팅의 (0), (1)을 참고해주세요.
(4) airflow 디렉토리를 만들고 Remote Repo를 Clone한 후, /keys, .env 파일은 직접 작성해줬어요.
git clone https://github.com/.../airflow.git
(5) 로컬 환경에서 세팅한 것과 마찬가지로 Docker Compose를 빌드한 후 실행했어요.
- 2.2. 로컬 환경 세팅의 (7), (8)을 참고해주세요.
(6) 로컬 환경에서 VM Instance Airflow Webserver에 접속하여 로그인했어요.
1) http://{VM Instance의 외부 IP 주소}:8080 로 접속해요.
2) docker-compose.yaml에서 설정했던 아래의 환경 변수로 로그인하면 돼요.
- _AIRFLOW_WWW_USER_USERNAME
- _AIRFLOW_WWW_USER_PASSWORD
2.4. DAG 만들기
제가 작성한 DAG 중 가장 간단한 것은 “매일 빅쿼리 사용량 알림”입니다. 구글 클라우드를 관리하고 있는 저의 안심(?)을 도모하기 위한 셀프 알림 목적을 지니고 있는데요. DAG.py 코드를 단계를 나누어 서술해드릴게요.
(1) 필요한 라이브러리 및 오퍼레이터를 불러왔어요.
# ========================================================================
# 라이브러리 및 환경변수 불러오기
# ========================================================================
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.providers.slack.operators.slack import SlackAPIPostOperator
from airflow.models import Variable
from google.cloud import bigquery
from pendulum import timezone
from datetime import datetime, timedelta
- BigQuery 관련 오퍼레이터를 사용하지 않고,
google.cloud.bigquery와PythonOperator를 사용했어요. Create, Insert, Update 작업이 아닌, Select 작업의 경우 응답 받아야 하는 데이터가 많으므로 Xcom을 활용하기에는 부적절하다고 판단했기 때문이에요.
(2) 중요한 변수들과 클라이언트를 정의했어요.
# ========================================================================
# 클라이언트 및 중요한 변수 정의
# ========================================================================
bigquery_client = bigquery.Client()
kst = timezone('Asia/Seoul')
SLACK_CHANNEL_TEST = Variable.get('slack-channel-test')
SLACK_CHANNEL = Variable.get(
'slack-channel-prod',
default_var=SLACK_CHANNEL_TEST,
)
- kst: Airflow의 시간대를 한국 기준으로 명시하기 위해
pendulum.timezone을 사용했어요. (Airflow는 기본적으로 UTC 기준의 시간대를 바라보고 있는데, 작업시 상당히 혼동스러울 수 있거든요.) - 슬랙 채널: 본 DAG는 최종적으로 슬랙 채널에 알림을 전송하는 Task로 끝나요. 따라서, “테스트 목적으로 만든 슬랙 채널”에 기본적으로 DAG를 실행한 후 문제가 없다면 비로소 타겟 슬랙 채널에 배포하는 것이 알림을 받아보는 동료들에게 좋은 인상을 줄 수 있을 거예요. 다음과 같이, Airflow Webserver 상에서 Variable을 추가해서 관리했어요.
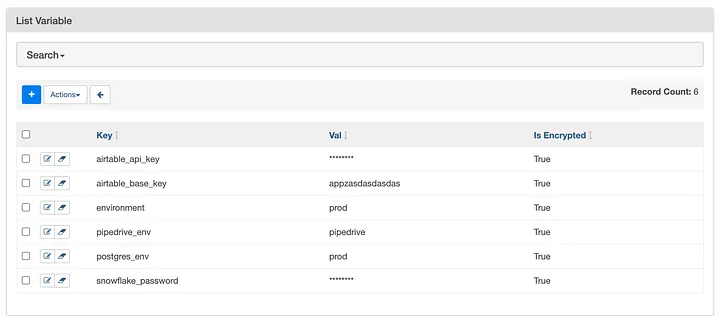
(3) DAG의 기본 Arguments를 Dictionary로 정의해줬어요.
# ========================================================================
# DAG Default Arguments 정의
# ========================================================================
default_args = {
'owner': '김진석의 이메일 주소',
'start_date': datetime(2025, 1, 1, tzinfo=kst),
'depends_on_past': False,
...
}
(4) 쿼리문을 동적으로 실행할 수 있도록 함수화했어요.
# ========================================================================
# 쿼리문 정의
# ========================================================================
...
# 총 사용량 (사용자별)
def query_usage_by_user(date):
return f"""
SELECT
user_email AS user,
SUM(total_bytes_billed) / POW(2, 30) AS gibibyte
FROM
`{project_id}.{region}.INFORMATION_SCHEMA.JOBS`
WHERE
DATE(TIMESTAMP(creation_time), "Asia/Seoul") = '{date}'
AND job_type = 'QUERY'
GROUP BY
1
ORDER BY
2 DESC
"""
...
(5) Task들을 실행할 주요 함수들을 작성했어요.
# ========================================================================
# 함수 정의
# ========================================================================
# BigQuery 데이터 추출
def fetch_bigquery_data(**kwargs):
# 어제 날짜 구하기
today_kst = kwargs['execution_date'].in_timezone(kst)
yesterday_kst = today_kst.subtract(days=1).to_date_string()
...
# 어제 총 사용량 (사용자별)
usage_by_user_df = bigquery_client.query(query_usage_by_user(yesterday_kst)).to_dataframe()
usage_by_user_dict = usage_by_user_df.set_index('user')['gibibyte'].to_dict()
# XComm으로 데이터 전달
...
kwargs['ti'].xcom_push(key='usage_by_user_dict', value=usage_by_user_dict)
...
# Slack 메시지 작성
def write_slack_message(**kwargs):
# BigQuery 결과 읽어오기
...
usage_by_user_dict = kwargs['ti'].xcom_pull(task_ids='fetch_bigquery_data', key='usage_by_user_dict')
# 메시지 만들기
message = f":bigquery: *전일 BigQuery 사용량 요약* (한국시각 기준)\n"
...
message += f"*:busts_in_silhouette: 사용자별*\n"
...
for user, usage in usage_by_user_dict.items():
message += f" - *{user}*: `{float(usage):,.2f}`GiB\n"
...
return message
(6) 마지막으로 DAG를 정의했어요.
# ========================================================================
# DAG 정의
# ========================================================================
with DAG(
'DAG.py 파일 이름과 동일하게 작성',
default_args = default_args,
description = 'BigQuery 사용량 알림',
schedule_interval = '5 0 * * *', # 매일 00:05 AM KST
catchup = False,
) as dag:
# BigQuery 데이터 추출
task_fetch_bigquery_data = PythonOperator(
task_id = 'fetch_bigquery_data',
python_callable = fetch_bigquery_data,
)
# Slack 메시지 작성
task_write_slack_message = PythonOperator(
task_id = 'write_slack_message',
python_callable = write_slack_message,
)
# Slack 메시지 전송
task_send_slack_message = SlackAPIPostOperator(
task_id = 'send_slack_message',
text = '',
slack_conn_id = 'slack_default',
channel = SLACK_CHANNEL,
)
# Task 간의 실행 순서 정의
task_fetch_bigquery_data >> task_write_slack_message >> task_send_slack_message
- 이 DAG는 다음과 같은 흐름으로 각 Task들을 실행해요.
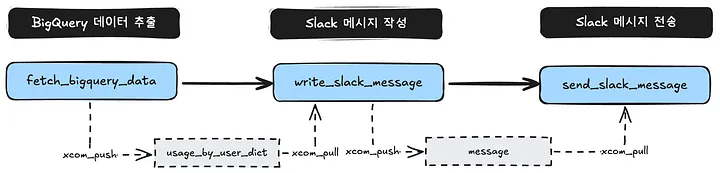
- 다음과 같은 슬랙 메시지가 전송되었어요.
3. 앞으로의 과제
사실, Linux나 Docker 환경에 익숙하지 않은 사람들에게 Airflow는 러닝 커브가 상당히 가파른 편이에요. 여러 가지 Orchestration 관리 도구 중 Airflow가 가장 자유도가 높은 만큼 어렵기 때문인데요. 하지만 Python에 상당히 익숙한 데이터 분석가, 애널리틱스 엔지니어, 그리고 백엔드 개발자라면 서로 커뮤니케이션을 하는 데 상당히 도움이 될 거예요.
사내에 본격적으로 Airflow를 도입한 후, 다음과 같은 “응용 버전”의 고민들이 추가로 생겼어요. 꼭 풀어가고 싶은 것들입니다.
- 외부 데이터 수집을 위한 파이프라인을 설계한 후, 정제된 데이터를 이해관계자 동료들에게 이메일이나 슬랙 DM으로 전송하기
- dbt의 각 테이블 의존성이나 최신화 주기 차이에 따라 배치 실행을 분리한 후 Airflow DAG로 관리하기
- 이 외에도 여러 가지 고민들
Airflow를 통해 유지보수 부담을 줄이고, 워크플로우의 안정성을 제고함으로써 개인적인 업무 효율화를 극대화할 수 있을 것으로 기대하고 있어요. 늘어난 가용 시간만큼 더욱 중요한 일에 몰입하여 동료들이 데이터를 더욱 잘 활용할 수 있는 환경을 만들 수 있기를 바라요. 개인적인 학습 뿐만 아니라, 기업의 성장과 고객의 만족을 위한 방향일테니까요.