
데이터 분석가의 SQL 최적화 일기: SELF JOIN을 피하는 방법
대고객 서빙을 위해 엄청나게 큰 사이즈의 소스 테이블로부터 최적화된 데이터 마트 설계 고민을 많이 하고 있는 만큼, 이번에는 SELF JOIN 사례를 중심으로 SQL 성능에 대한 이야기를 들려드리겠습니다.
CONTENTS
- 들어가는 글
- Python과 달리 거칠게 사고해야 하는 SQL
- SELF JOIN을 하면 연산량이 제곱으로 늘어난다.
- Subquery와 EXISTS 사용하기
- 결론: 무조건적 우월성은 없다.
DISCLAIMER
본 자료는 작성자 본인의 견해일 뿐이며, 실제 데이터베이스의 환경에 따라 적합하지 않을 수 있습니다. 이미지 출처를 제외한 모든 쿼리문과 내용은 본인의 경험에 의해 작성되었습니다. 작성된 쿼리문은 샘플로 작성한 것이며, 본인의 과거 및 현재 재직 회사의 업무 현황과 무관합니다.
1. 들어가는 글

{kind=link}
안녕하세요. 저는 친구들 얼굴을 보면 위와 같은 이상한 생각을 하는 데이터 분석가 Joshua라고 합니다.
저는 일반적인 B2C 기업에서 데이터 분석가로 근무하며, GA4, Amplitude, BigQuery, Redash 등을 활용하여 A/B 테스트, 지표 모니터링 등을 수행하며 회사의 등대 역할을 하며 지냈습니다. 다른 분들과 비슷한 역할을 수행했던 것이죠.
또한 GA4, Amplitude 등과 같은 B2B 데이터 분석 플랫폼 서비스를 만드는 경험도 살짝 했는데요. 그러다보니 저의 R&R은 서비스 자체의 데이터 분석 업무 외에도, 고객들에게 데이터를 서빙하기 위한 데이터 마트 설계와 최적화 업무에 집중되기도 했습니다. 제 타이틀을 멋있게 가공하면 최근에 떠오르는 포지션인 Analytics Engineer, 반쪽 짜리 데이터 엔지니어, 아니면 대충 쿼리 머신 혹은 분지니어(?)인 것 같기도 합니다. 😅
대고객 서빙을 위해 엄청나게 큰 사이즈의 소스 테이블로부터 최적화된 데이터 마트 설계 고민을 많이 하고 있는 만큼, 이번에는 SELF JOIN 사례를 중심으로 SQL 성능에 대한 이야기를 들려드리겠습니다. (SQL 전문가 분들이 많이 계시는 만큼, 제 글을 비판적으로 고찰해주시면 감사하겠습니다! 😄)
쿼리로 고통 받으며 눈동자에 비가 내렸던 경험 이야기, 시작합니다! (울지마~ 울지마~ 울지마~)

2. Python과 달리 거칠게 사고해야 하는 SQL
SQL을 통해 OLAP(Online Analytical Processing)에 해당하는 데이터 웨어하우스를 구축하다보면, 종종 SELF JOIN이 필요합니다. 가령, 소스 테이블의 복사본인 Staging Table을 Pivoting 해야 하거나, 칼럼 A와 칼럼 B 간의 관계 규칙을 찾아 Data Cleaning을 해야 하는 경우에 특히 발생하는 것 같았어요.
가령, Python의 Pandas Dataframe 환경에서는 메소드를 통해 너무나도 쉽게 Pivoting을 하거나, 반복문과 조건문을 통해 칼럼 사이의 관계 규칙을 고작 몇 줄 코드 만으로 Data Cleaning을 할 수 있을 것입니다.
pandas.DataFrame.pivot
pandas.apply(lambda x: value if condition is true if x condition else value of condition is false)
하지만 안타깝게도 SQL에서는 다소 거친 방법으로 쿼리문을 작성해야 하므로 좀 더 테이블 자체를 기반의 Logical Thinking을 하는 것이 중요합니다.
가령 다음 기본적인 사례와 같이, 국가 별로 MAU를 집계할 경우에 SQL은 훨씬 거칠게 표현합니다.
SELECT
DATE_TRUNC('MONTH', datetime) AS yyyymm,
country,
COUNT(DISTINCT user_id) AS mau
FROM
source_events
GROUP BY
1, 2
ORDER BY
1, 2
;
source_events['yyyymm'] = pd.to_datetime(source_events['datetime']).dt.to_period('M')
result_df = source_events.groupby(['yyyymm', 'country']).agg(mau=('user_id', 'nunique')).reset_index(drop=False)
result_df = result_df.sort_values(by=['yyyymm', 'country']).reset_index(drop=True)
print(result_df)
즉, 파이썬의 to_period, groupby, nunique 등과 같은 내장 메소드의 연산 원리를 이해하여 이를 DATE_TRUNC, COUNT(DISTINCT …), GROUP BY 등의 SQL 함수와 Statement로 표현해야 하는 것이죠.
3. SELF JOIN을 하면 연산량이 제곱으로 늘어난다.
먼저 다음과 같은 쿼리문 사례를 살펴보도록 하죠.
SELECT
MAIN.datetime,
MAIN.user_id,
MAIN.session_id,
MAIN.event_index,
MAIN.event_param_index,
MAIN.event_param_key,
MAIN.event_param_value
FROM
source_events MAIN
LEFT JOIN
source_events SUB
ON MAIN.user_id = SUB.user_id
AND MAIN.session_id = SUB.session_id
AND MAIN.event_index = SUB.event_index
WHERE
MAIN.event_param_index = SUB.event_param_index + 0
OR MAIN.event_param_index = SUB.event_param_index + 1
OR MAIN.event_param_index = SUB.event_param_index + 2
OR MAIN.event_param_index = SUB.event_param_index + 3
위 사례는 가령 이런 상황으로 이해하시면 될 것 같습니다. 사용자의 이벤트 로그 소스 테이블에서 각 이벤트의 파라미터 key-value가 unnested된 상태로 존재하거나, 혹은 특정 파라미터의 index를 기준으로 인접한 파라미터 정보들만 추출해야 하는 상황에서 위와 같은 쿼리문 작성이 필요할 것입니다.
SQL의 연산 과정은 FROM → XXX JOIN → WHERE → GROUP BY → SELECT → HAVING → ORDER BY 등의 순으로 진행되는데요. 위 쿼리문을 연산하는 과정에서 WHERE Statement에 진입하기 전에, 먼저 FROM과 LEFT JOIN을 통해 모든 Row를 메모리에 로드하게 됩니다.
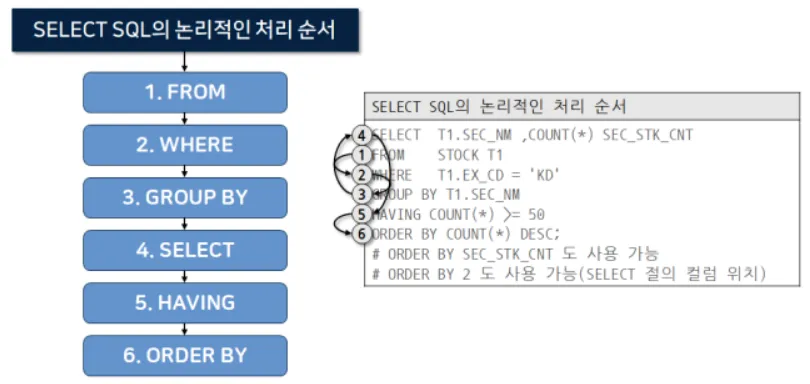
{kind=link}
가령, source_events 테이블이 1,000,000개의 Row로 구성되어 있다면, 최대 1,000,000 * 1,000,000개의 Row가 메모리에 올라오게 되는 것이죠. 이는 쿼리 엔진의 메모리 및 트래픽 DevOps 환경이 중요한 경우 분명히 문제가 됩니다. 혹은 Usage Limit이 걸려 있을 경우에는 쿼리 실행이 몇 시간 동안 진행되다가 아침에 눈을 떠보면 트래픽 제한으로 인해 실행이 실패되었다는 매우 슬프고 참담한 상황에 마주하게 될 것입니다.

{kind=link}
그렇다면, 이런 상황에서 어떻게 쿼리를 최적화할 수 있을까요?
4. Subquery와 EXISTS 사용하기
위에서 보셨던 쿼리문을 아래와 같이 수정해봤습니다.
SELECT
datetime,
user_id,
session_id,
event_index,
event_param_index,
event_param_key,
event_param_value
FROM
source_events MAIN
WHERE
EXISTS (
SELECT 1
FROM source_events SUB
WHERE
event_type = 'click_button'
AND MAIN.user_id = SUB.user_id
AND MAIN.session_id = SUB.session_id
AND MAIN.event_index = SUB.event_index
AND (
MAIN.event_param_index = SUB.event_param_index + 0
OR MAIN.event_param_index = SUB.event_param_index + 1
OR MAIN.event_param_index = SUB.event_param_index + 2
OR MAIN.event_param_index = SUB.event_param_index + 3
)
)
자, 어떻게 달라졌는지 차근차근 살펴보도록 하죠.
1. 먼저, LEFT JOIN이 사라지고, WHERE Statement의 Subquery가 추가되었습니다.
JOIN보다 Subquery가 반드시 모든 상황에서 성능이 우월하지는 않지만, 이 상황에서는 메모리 데이터의 사이즈는 상당 부분 해소되었습니다. 앞서 말씀 드린 것처럼, SQL은 WHERE Statement를 고려하기 전에 먼저 FROM과 LEFT JOIN을 먼저 실행하게 되는데, WHERE Statement의 Subquery로 옮김으로써 LEFT JOIN에서 실행되어야 하는 작업을 WHERE에서 동시에 연산하여 메모리에 올릴 수 있게 되었습니다.
가령, source_events 테이블의 Row 수가 1,000,000개 이고, WHERE를 통해 Filter out된 Row 수가 10,000개라면, 메모리에 올라가게 되는 Row 수는 이전의 최대 1,000,000 * 1,000,000개에서 1,000,000 * 10,000개로 1% 수준으로 급감하였습니다.
2. IN보다 EXISTS가 연산 속도가 더 빠릅니다.
IN과 EXISTS 모두 “XXX한 경우가 존재하니?”를 질문하는 과정으로 추상화할 수 있을 것 같은데요.
만약 IN을 통해 Filter out하려고 하면 가령 아래와 같은 쿼리문을 작성해야 합니다.
WHERE
MAIN.event_param_index IN (SELECT SUB.event_param_index + 0 FROM ...)
AND MAIN.event_param_index IN (SELECT SUB.event_param_index + 1 FROM ...)
AND MAIN.event_param_index IN (SELECT SUB.event_param_index + 2 FROM ...)
AND MAIN.event_param_index IN (SELECT SUB.event_param_index + 3 FROM ...)
...
위 과정은 한 가지 단점이 있습니다. SUB.event_param_index 칼럼의 값들을 일일이 출력해야 하는데요. 즉, 다양한 값들로 구성된 칼럼을 메모리에 로드해야 한다는 것이죠.
그러나 EXISTS를 통해 Filter out하려고 하면 아래와 같은 쿼리문으로 수정될 수 있습니다.
WHERE
EXISTS (
SELECT 1
FROM ...
WHERE
...
AND (
MAIN.event_param_index = SUB.event_param_index + 0
OR MAIN.event_param_index = SUB.event_param_index + 1
OR MAIN.event_param_index = SUB.event_param_index + 2
OR MAIN.event_param_index = SUB.event_param_index + 3
)
이 과정은 위에서 말씀 드린 IN의 단점을 상당 부분 해소합니다. SUB.event_param_index 칼럼의 값들을 일일이 출력했던 것과 달리, 이번에는 조건을 만족하기만 하면 단순히 일괄적으로 1로만 구성된 칼럼을 메모리에 로드하게 됩니다. Data Type 측면에서 훨씬 메모리의 부담을 경감시킬 수 있습니다. (혹은 1이 아니라, True나 False와 같은 Boolean 타입으로 출력하면 더 확실하게 경감시킬 수 있을 것 같네요.)
5. 결론: 무조건적 우월성은 없다.
자 이제 다시 최적화된 쿼리문 전체를 보시죠.
SELECT
datetime,
user_id,
session_id,
event_index,
event_param_index,
event_param_key,
event_param_value
FROM
source_events MAIN
WHERE
EXISTS (
SELECT 1
FROM source_events SUB
WHERE
event_type = 'click_button'
AND MAIN.user_id = SUB.user_id
AND MAIN.session_id = SUB.session_id
AND MAIN.event_index = SUB.event_index
AND (
MAIN.event_param_index = SUB.event_param_index + 0
OR MAIN.event_param_index = SUB.event_param_index + 1
OR MAIN.event_param_index = SUB.event_param_index + 2
OR MAIN.event_param_index = SUB.event_param_index + 3
)
)
프로그래밍에는 반드시 “방법 A가 방법 B보다 우월하다.”라는 것은 존재하지 않은 것처럼, 각자의 환경에 따라 취사선택하며 최적화를 하는 것이 중요할 것입니다.
WHERE Statement의 Subquery가 JOIN보다 반드시 우월한 것도 아니고, 경우에 따라 EXISTS가 IN보다 반드시 뛰어난 성능을 보이지 않을 수도 있습니다.
또한, 일반적으로 Subquery와 EXISTS 문법은 SQL 초급 사용자 분들께는 살짝 팔로업하기 어려울 수 있으므로, 가독성 측면에서 추후 유지보수의 장애로 작용할 수도 있을 것입니다.

{kind=link}
앞으로, 대용량의 데이터 소스를 다루시다가 SELF JOIN 때문에 트래픽 문제가 발생하신다면 위와 같은 사례로도 접근 가능하다는 점을 참고하시고, 각자 처한 환경에 따라 최적화하여 가성비 좋은 데이터 분석을 하시길 바랄게요. 부족한 글을 읽어주셔서 감사합니다!

퇴사하겠다는 의미가 아니라, 계속 쿼리 작성하러 가겠다는 의미
Published by Joshua Kim
