
How to Share dbt Docs Internally (Site Hosting Review)
“I worked on automating data warehouse documentation using dbt Docs within the company, aiming to improve internal data accessibility and efficiency. Specifically, I utilized dbt’s automated documentation feature to keep dependencies between tables and specifications up to date, thereby improving the accuracy and speed of data usage. I successfully built the system by resolving technical issues, such as hosting dbt Docs on a VM instance and adding firewall settings to allow internal team members to access it within the company’s IP range.”
Table of Contents
- What is dbt Docs?
- Background
- Objective
- Process
- Conclusion
1. What is dbt Docs?
dbt is an automation framework specialized in the transformation phase of the ELT pipeline, widely used by data analysts and analytics engineers.
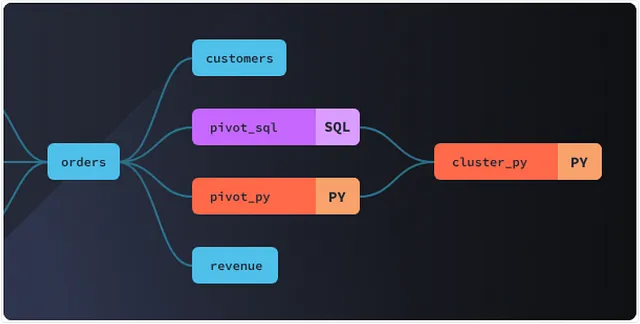
dbt analyzes data lineage based on table dependencies and compiles it into a DAG (Directed Acyclic Graph) to automatically execute the entire transformation process. This enables more efficient orchestration management of data warehouses. One of dbt’s key strengths is its “automated documentation” feature.
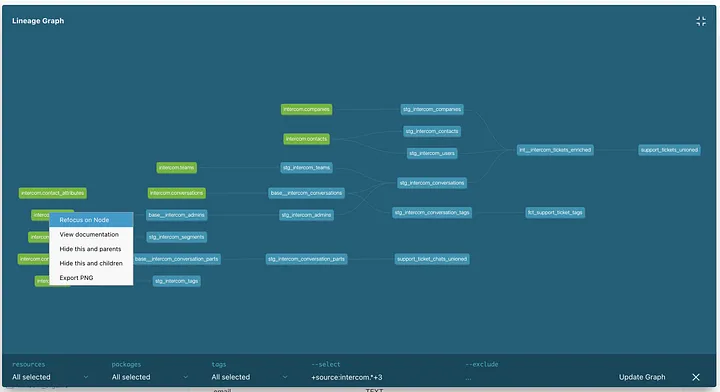
(1) Lineage Graph: Visually displays table dependencies, allowing you to easily identify the tables affected during maintenance tasks.
(2) View Specifications: Easily check detailed specifications, such as descriptions of each table and column.
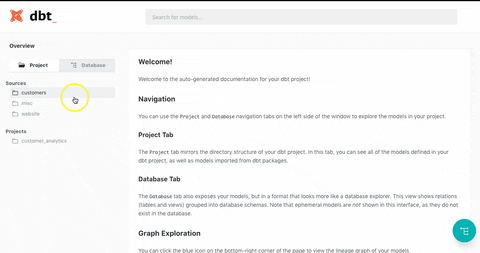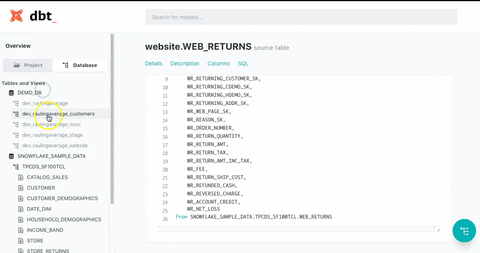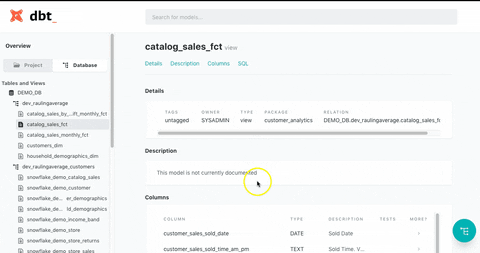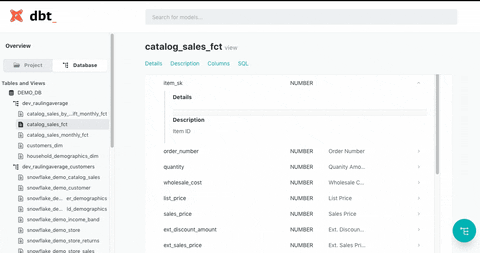
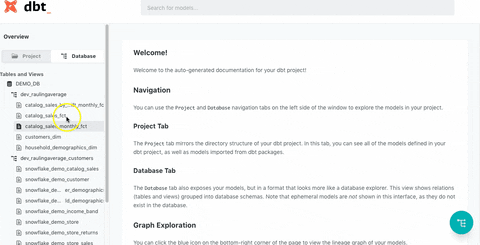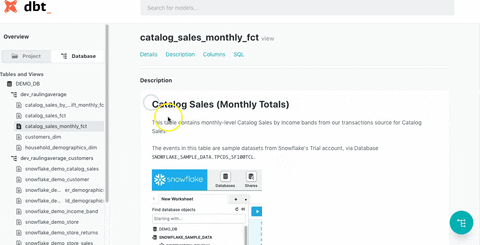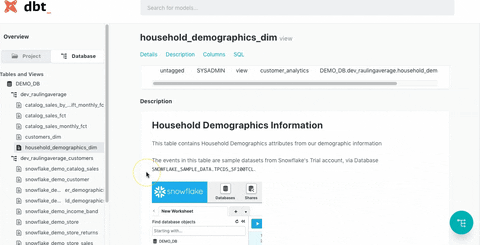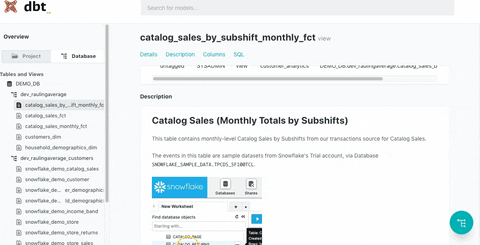
dbt Docs is highly effective in addressing major pain points for data teams. While many companies adopt data warehouses to enhance data utilization, they often face the ironic situation where the complexity of numerous data marts and table structures reduces internal accessibility. As the organization’s dependence on data increases with the rapid growth of its products, maintaining quality, accuracy, accessibility, and documentation can become increasingly difficult.
dbt solves this problem by automatically documenting the entire data warehouse, playing a key role in improving data quality and usability.
2. Background
I wanted to provide an environment where internal members with query-writing skills could view table and lineage documentation and directly create Redash dashboards. In other words, data warehouse documentation was necessary. Although I considered using Google Sheets or Notion pages, I was concerned that separating analytics engineering and documentation tasks could lead to the following issues:
- Communication could slow down due to latency between data mart creation and documentation.
- Human error during individual documentation could result in inaccurate query outcomes.
Thus, I concluded that it was not ideal for the documentation environment to be separated from the core analytics engineering work. I wanted to reduce repetitive tasks and spend more time creating value in more critical areas.
3. Objective
The goal of this project was to host a dbt Docs site where internal members could check the latest specifications as soon as the dbt project version was updated.
4. Process
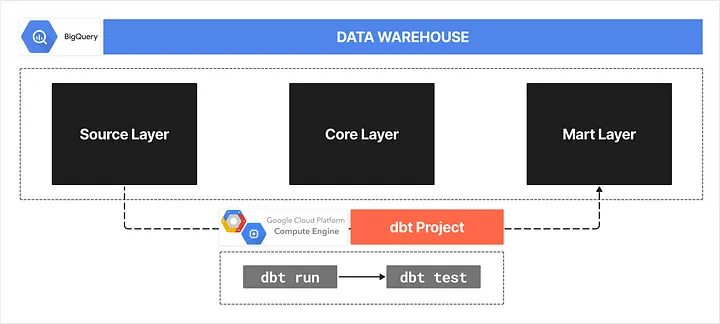
4.1. Current dbt Project Management
I’ve been working on converting source tables into Core Layer and Mart Layer within the BigQuery project.
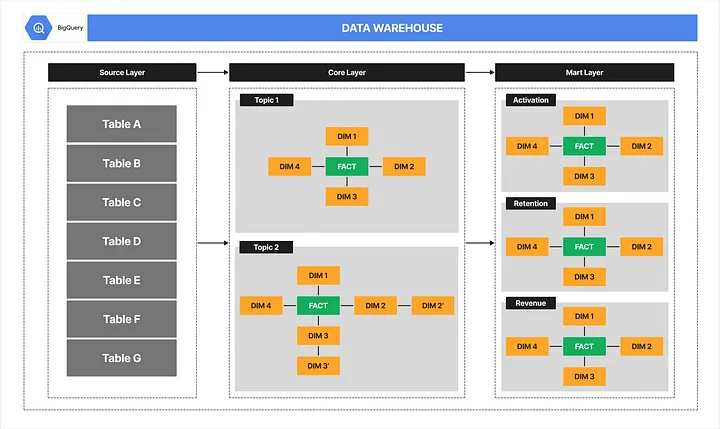
All transformation processes are periodically executed via a dbt project on a Google Cloud VM instance.
4.2. Issues with Local Hosting
As with other frameworks, hosting dbt Docs is, by default, only accessible from the host machine. In other words, you can only access it from the VM instance where the dbt project is located or from a locally connected machine via SSH.
However, I needed to create an environment where internal members could also access it. In short, I had to allow machines within the same IP range, but without SSH keys, to access the dbt Docs site.

4.3. Starting dbt Docs Hosting
Here are the steps I followed to set up the internal access environment:
(1) Create a tmux session
I used tmux to create an independent session on the VM instance to maintain the dbt Docs hosting.
tmux new -s dbt_docs # Create a session named dbt_docs
tmux attach -t dbt_docs # Attach to the dbt_docs session
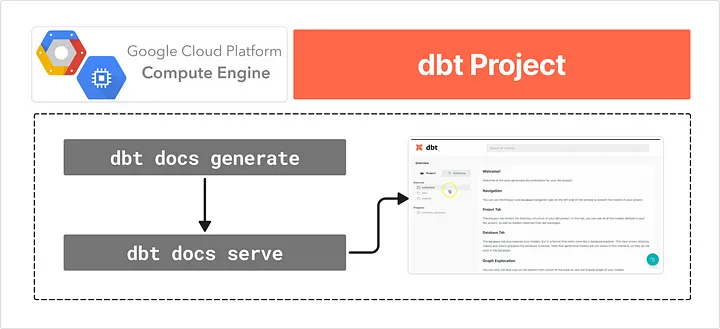
(2) Build the site
I compiled the dbt project files to build the Docs site.
source dbt-venv/bin/activate # Activate Python Virtual Environment
export DBT_PROFILES_DIR="path/to/profiles.yml" # Define the DBT_PROFILES_DIR environment variable
dbt docs generate --target prod # Build dbt Docs based on the prod schema
(3) Start hosting the site
I started hosting the Docs site and detached from the session.
dbt docs serve --host 0.0.0.0 --port 8080 # Specify the host domain and port as parameters
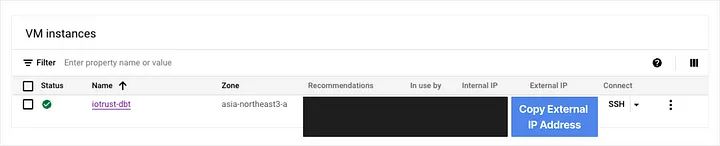
(4) Set up the VM Instance
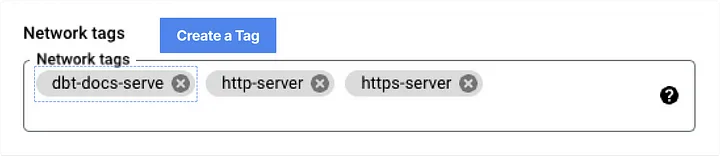
I checked the VM instance’s external IP and added a network tag on the modification page.
(5) Add VPC firewall rules
I went to the firewall policies console and added VPC firewall rules as follows:
- Direction: Ingress
- Source IPv4 Range: Internal IPv4 range (CIDR format)
- Target Tags: The network tag added to the VM instance earlier (dbt-docs-serve)
- Protocol and Port: Port for the dbt Docs hosting (8080)
(6) Access address
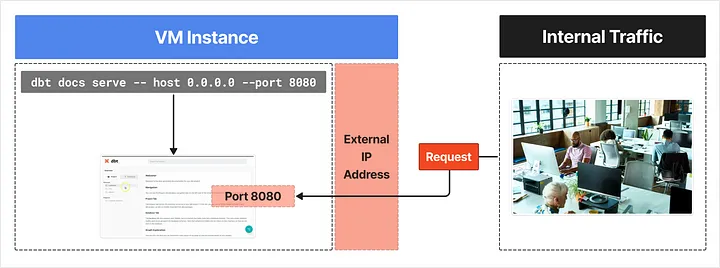
Now, from within the internal IPv4 range, you can access the site via the following address:
http://{VM Instance의 External IP}:8080
(7) In summary, the configured environment is as follows:
“Within the internal IPv4 range, you can access the hosted dbt Docs site by connecting to the VM instance’s external IP address on port 8080!”
5. Conclusion
I pinned the dbt Docs site link in the Slack channel to allow team members to easily access it later. As the company and product continue to grow, the demand for data utilization will increase. By leveraging dbt’s “automated documentation” feature, we can save documentation resources and enhance the efficiency of data-related tasks.
Published by Joshua Kim
